"Stubs" in the .NET Runtime
26 Sep 2019 - 12019 wordsAs the saying goes:
“All problems in computer science can be solved by another level of indirection”
and it certainly seems like the ‘.NET Runtime’ Engineers took this advice to heart!
‘Stubs’, as they’re known in the runtime (sometimes ‘Thunks’), provide a level of indirection throughout the source code, there’s almost 500 mentions of them!
This post will explore what they are, how they work and why they’re needed.
Table of Contents
What are stubs?
In the context of the .NET Runtime, ‘stubs’ look something like this:
Call-site Callee
+--------------+ +---------+ +-------------+
| | | | | |
| +---------->+ Stub + - - - - ->+ |
| | | | | |
+--------------+ +---------+ +-------------+
So they sit between a method ‘call-site’ (i.e. code such as var result = Foo(..);) and the ‘callee’ (where the method itself is implemented, the native/assembly code) and I like to think of them as doing tidy-up or fix-up work. Note that moving from the ‘stub’ to the ‘callee’ isn’t another full method call (hence the dotted line), it’s often just a single jmp or call assembly instruction, so the 2nd transition doesn’t involve all the same work that was initially done at the call-site (pushing/popping arguments into registers, increasing the stack space, etc).
The stubs themselves can be as simple as just a few assembly instructions or something more complicated, we’ll look at individual examples later on in this post.
Now, to be clear, not all method calls require a stub, if you’re doing a regular call to an static or instance method that just goes directly from the ‘call-site’ to the ‘callee’. But once you involve virtual methods, delegates or generics things get a bit more complicated.
Why are stubs needed?
There are several reasons that stubs need to be created by the runtime:
- Required Functionality
- For instance Delegates and Arrays must be provided but the runtime, their method bodies are not generated by the C#/F#/VB.NET compiler and neither do they exist in the Base-Class Libraries. This requirement is outlined in the ECMA 355 Spec, for instance ‘Partition I’ in section ‘8.9.1 Array types’ says:
Exact array types are created automatically by the VES when they are required. Hence, the operations on an array type are defined by the CTS. These generally are: allocating the array based on size and lower-bound information, indexing the array to read and write a value, computing the address of an element of the array (a managed pointer), and querying for the rank, bounds, and the total number of values stored in the array.
Likewise for delegates, which are covered in ‘I.8.9.3 Delegates’:
While, for the most part, delegates appear to be simply another kind of user-defined class, they are tightly controlled. The implementations of the methods are provided by the VES, not user code. The only additional members that can be defined on delegate types are static or instance methods.
- For instance Delegates and Arrays must be provided but the runtime, their method bodies are not generated by the C#/F#/VB.NET compiler and neither do they exist in the Base-Class Libraries. This requirement is outlined in the ECMA 355 Spec, for instance ‘Partition I’ in section ‘8.9.1 Array types’ says:
- Performance
- Other types of ‘stubs’, such as Virtual Stub Dispatch and Generic Instantiation Stubs are there to make those operations perform well or to have an positive impact on the entire runtime, such as reducing the memory footprint (in the case of ‘shared generic code’).
- Consistent method calls
- A final factor is that having ‘stubs’ makes the work of the JIT compiler easier. As we will see in the rest of the post, stubs deal with a variety of different types of method calls. This means the the JIT can generate more straightforward code for any given ‘call site’, because it (mostly) doesn’t care whats happening in the ‘callee’. If stubs didn’t exist, for a given method call the JIT would have to generate different code depending on whether generics where involved or not, if it was a virtual or non-virtual call, if it was going via a delegate, etc. Stubs abstact a lot of this behaviour away from the JIT, allowing it to deal with a more simple ‘Application Binary Interface’ (ABI).
CLR ‘Application Binary Interface’ (ABI)
Therefore, another way to think about ‘stubs’ is that they are part of what makes the CLR-specific ‘Application Binary Interface’ (ABI) work.
All code needs to work with the ABI or ‘calling convention’ of the CPU/OS that it’s running on, for instance by following the x86 calling convention, x64 calling convention or System V ABI. This applies across runtimes, for more on this see:
- The Go low-level calling convention on x86-64
- What’s the calling convention for the Java code in Linux platform?
- Rust docs - Foreign Function Interface
- Rust docs - abi_thiscall
- rustgo: calling Rust from Go with near-zero overhead
As an aside, if you want more information about ‘calling conventions’ here’s some links that I found useful:
- Calling Conventions Demystified
- OS Dev - Calling Conventions
- x64 ABI: Intro to the Windows x64 calling convention
- x64 ABI vs. x86 ABI (aka Calling Conventions for AMD64 & EM64T)
However, on-top of what the CLR has to support due to the CPU/OS conventions, it also has it’s own extended ABI for .NET-specific use cases, including:
- “this” pointer:
The managed “this” pointer is treated like a new kind of argument not covered by the native ABI, so we chose to always pass it as the first argument in (AMD64)
RCXor (ARM, ARM64)R0. AMD64-only: Up to .NET Framework 4.5, the managed “this” pointer was treated just like the native “this” pointer (meaning it was the second argument when the call used a return buffer and was passed inRDXinstead ofRCX). Starting with .NET Framework 4.5, it is always the first argument. - Generics or more specifically to handle ‘Shared generics’:
In cases where the code address does not uniquely identify a generic instantiation of a method, then a ‘generic instantiation parameter’ is required. Often the “this” pointer can serve dual-purpose as the instantiation parameter. When the “this” pointer is not the generic parameter, the generic parameter is passed as an additional argument..
- Hidden Parameters, covering ‘Stub dispatch’, ‘Fast Pinvoke’, ‘Calli Pinvoke’ and ‘Normal PInvoke’. For instance, here’s why ‘PInvoke’ has a hidden parameter:
Normal PInvoke - The VM shares IL stubs based on signatures, but wants the right method to show up in call stack and exceptions, so the MethodDesc for the exact PInvoke is passed in the (x86)
EAX/ (AMD64)R10/ (ARM, ARM64)R12(in the JIT:REG_SECRET_STUB_PARAM). Then in the IL stub, when the JIT getsCORJIT_FLG_PUBLISH_SECRET_PARAM, it must move the register into a compiler temp.
Not all of these scenarios need a stub, for instance the ‘this’ pointer is handled directly by the JIT, but many do as we’ll see in the rest of the post.
Stub Management
So we’ve seen why stubs are needed and what type of functionality they can provide. But before we look at all the specific examples that exist in the CoreCLR source, I just wanted to take some time to understand the common or shared concerns that apply to all stubs.
Stubs in the CLR are snippets of assembly code, but they have to be stored in memory and have their life-time managed. Also, they have to play nice with the debugger, from What Every CLR Developer Must Know Before Writing Code:
2.8 Is your code compatible with managed debugging?
- ..
- If you add a new stub (or way to call managed code), make sure that you can source-level step-in (F11) it under the debugger. The debugger is not psychic. A source-level step-in needs to be able to go from the source-line before a call to the source-line after the call, or managed code developers will be very confused. If you make that call transition be a giant 500 line stub, you must cooperate with the debugger for it to know how to step-through it. (This is what StubManagers are all about. See src\vm\stubmgr.h). Try doing a step-in through your new codepath under the debugger.
So every type of stub has a StubManager which deals with the allocation, storage and lookup of the stubs. The lookup is significant, as it provides the mapping from an arbitrary memory address to the type of stub (if any) that created the code. As an example, here’s what the CheckIsStub_Internal(..) method here and DoTraceStub(..) method here look like for the DelegateInvokeStubManager:
BOOL DelegateInvokeStubManager::CheckIsStub_Internal(PCODE stubStartAddress)
{
LIMITED_METHOD_DAC_CONTRACT;
bool fIsStub = false;
#ifndef DACCESS_COMPILE
#ifndef _TARGET_X86_
fIsStub = fIsStub || (stubStartAddress == GetEEFuncEntryPoint(SinglecastDelegateInvokeStub));
#endif
#endif // !DACCESS_COMPILE
fIsStub = fIsStub || GetRangeList()->IsInRange(stubStartAddress);
return fIsStub;
}
BOOL DelegateInvokeStubManager::DoTraceStub(PCODE stubStartAddress, TraceDestination *trace)
{
LIMITED_METHOD_CONTRACT;
LOG((LF_CORDB, LL_EVERYTHING, "DelegateInvokeStubManager::DoTraceStub called\n"));
_ASSERTE(CheckIsStub_Internal(stubStartAddress));
// If it's a MC delegate, then we want to set a BP & do a context-ful
// manager push, so that we can figure out if this call will be to a
// single multicast delegate or a multi multicast delegate
trace->InitForManagerPush(stubStartAddress, this);
LOG_TRACE_DESTINATION(trace, stubStartAddress, "DelegateInvokeStubManager::DoTraceStub");
return TRUE;
}
The code to initialise the various stub managers is here in SystemDomain::Attach() and by working through the list we can get a sense of what each category of stub does (plus the informative comments in the code help!)
PrecodeStubManagerimplemented here- ‘Stub manager functions & globals’
DelegateInvokeStubManagerimplemented here- ‘Since we don’t generate delegate invoke stubs at runtime on IA64, we can’t use the StubLinkStubManager for these stubs. Instead, we create an additional DelegateInvokeStubManager instead.’
JumpStubStubManagerimplemented here- ‘Stub manager for jump stubs created by ExecutionManager::jumpStub() These are currently used only on the 64-bit targets IA64 and AMD64’
RangeSectionStubManagerimplemented here- ‘Stub manager for code sections. It forwards the query to the more appropriate stub manager, or handles the query itself.’
ILStubManagerimplemented here- ‘This is the stub manager for IL stubs’
InteropDispatchStubManagerimplemented here- ‘This is used to recognize GenericComPlusCallStub, VarargPInvokeStub, and GenericPInvokeCalliHelper.’
StubLinkStubManagerimplemented hereThunkHeapStubManagerimplemented here- ‘Note, the only reason we have this stub manager is so that we can recgonize UMEntryThunks for IsTransitionStub. ..’
TailCallStubManagerimplemented here- ‘This is the stub manager to help the managed debugger step into a tail call. It helps the debugger trace through JIT_TailCall().’ (from stubmgr.h)
ThePreStubManagerimplemented here (in prestub.cpp)- ‘The following code manages the PreStub. All method stubs initially use the prestub.’
VirtualCallStubManagerimplemented here (in virtualcallstub.cpp)- ‘VirtualCallStubManager is the heart of the stub dispatch logic. See the book of the runtime entry’ (BOTR - Virtual Stub Dispatch)
Finally, we can also see the ‘StubManagers’ in action if we use the eeheap SOS command to inspect the ‘heap dump’ of a .NET Process, as it helps report the size of the different ‘stub heaps’:
> !eeheap -loader
Loader Heap:
--------------------------------------
System Domain: 704fd058
LowFrequencyHeap: Size: 0x0(0)bytes.
HighFrequencyHeap: 002e2000(8000:1000) Size: 0x1000(4096)bytes.
StubHeap: 002ea000(2000:1000) Size: 0x1000(4096)bytes.
Virtual Call Stub Heap:
- IndcellHeap: Size: 0x0(0)bytes.
- LookupHeap: Size: 0x0(0)bytes.
- ResolveHeap: Size: 0x0(0)bytes.
- DispatchHeap: Size: 0x0(0)bytes.
- CacheEntryHeap: Size: 0x0(0)bytes.
Total size: 0x2000(8192)bytes
--------------------------------------
(output taken from .NET Generics and Code Bloat (or its lack thereof))
You can see that in this case the entire ‘stub heap’ is taking up 4096 bytes and in addition there are more in-depth statistics covering the heaps used by virtual call dispatch.
Types of stubs
The different stubs used by the runtime fall into 3 main categories:
- Hand-written assembly code e.g. /vm/amd64/PInvokeStubs.asm
- Dynamically emitted assembly code, implemented in C++, e.g.
StubLinkerCPU::EmitShuffleThunk(..)in /vm/arm64/stubs.cpp - ‘Stubs-as-IL’ which we discuss later on in this post, for example
COMDelegate::GetMulticastInvoke(..)in /vm/comdelegate.cpp
Most stubs are wired up in MethodDesc::DoPrestub(..), in this section of code or this section for COM Interop. The stubs generated include the following (definitions taken from BOTR - ‘Kinds of MethodDescs’, also see enum MethodClassification here):
- Instantiating in (
FEATURE_SHARE_GENERIC_CODE, on by default) inMakeInstantiatingStubWorker(..)here- Used for less common IL methods that have generic instantiation or that do not have preallocated slot in method table.
- P/Invoke (a.k.a NDirect) in
GetStubForInteropMethod(..)here- P/Invoke methods. These are methods marked with DllImport attribute.
- FCall methods in
ECall::GetFCallImpl(..)here- Internal methods implemented in unmanaged code. These are methods marked with
MethodImplAttribute(MethodImplOptions.InternalCall)attribute, delegate constructors and tlbimp constructors.
- Internal methods implemented in unmanaged code. These are methods marked with
- Array methods in
GenerateArrayOpStub(..)here- Array methods whose implementation is provided by the runtime (Get, Set, Address)
- EEImpl in
PCODE COMDelegate::GetInvokeMethodStub(EEImplMethodDesc* pMD)here- Delegate methods, implementation provided by the runtime
- COM Interop (
FEATURE_COMINTEROP, on by default) inGetStubForInteropMethod(..)here- COM interface methods. Since the non-generic interfaces can be used for COM interop by default, this kind is usually used for all interface methods.
- Unboxing in
Stub * MakeUnboxingStubWorker(MethodDesc *pMD)here
Right, now lets look at the individual stub in more detail.
Precode
First up, we’ll take a look at ‘precode’ stubs, because they are used by all other types of stubs, as explained in the BotR page on Method Descriptors:
The precode is a small fragment of code used to implement temporary entry points and an efficient wrapper for stubs. Precode is a niche code-generator for these two cases, generating the most efficient code possible. In an ideal world, all native code dynamically generated by the runtime would be produced by the JIT. That’s not feasible in this case, given the specific requirements of these two scenarios. The basic precode on x86 may look like this:
mov eax,pMethodDesc // Load MethodDesc into scratch register jmp target // Jump to a targetEfficient Stub wrappers: The implementation of certain methods (e.g. P/Invoke, delegate invocation, multi dimensional array setters and getters) is provided by the runtime, typically as hand-written assembly stubs. Precode provides a space-efficient wrapper over stubs, to multiplex them for multiple callers.
The worker code of the stub is wrapped by a precode fragment that can be mapped to the MethodDesc and that jumps to the worker code of the stub. The worker code of the stub can be shared between multiple methods this way. It is an important optimization used to implement P/Invoke marshalling stubs.
By providing a ‘pointer’ to the MethodDesc class, the precode allows any subsequent stub to have access to a lot of information about a method call and it’s containing Type via the MethodTable (‘hot’) and EEClass (‘cold’) data structures. The MethodDesc data-structure is one of the most fundamental types in the runtime, hence why it has it’s own BotR page.
Each ‘precode’ is created in MethodDesc::GetOrCreatePrecode() here and there are several different types as we can see in this enum from /vm/precode.h:
enum PrecodeType {
PRECODE_INVALID = InvalidPrecode::Type,
PRECODE_STUB = StubPrecode::Type,
#ifdef HAS_NDIRECT_IMPORT_PRECODE
PRECODE_NDIRECT_IMPORT = NDirectImportPrecode::Type,
#endif // HAS_NDIRECT_IMPORT_PRECODE
#ifdef HAS_FIXUP_PRECODE
PRECODE_FIXUP = FixupPrecode::Type,
#endif // HAS_FIXUP_PRECODE
#ifdef HAS_THISPTR_RETBUF_PRECODE
PRECODE_THISPTR_RETBUF = ThisPtrRetBufPrecode::Type,
#endif // HAS_THISPTR_RETBUF_PRECODE
};
As always, the BotR page describes the different types in great detail, but in summary:
- StubPrecode - .. is the basic precode type. It loads MethodDesc into a scratch register and then jumps. It must be implemented for precodes to work. It is used as fallback when no other specialized precode type is available.
- FixupPrecode - .. is used when the final target does not require MethodDesc in scratch register. The FixupPrecode saves a few cycles by avoiding loading MethodDesc into the scratch register. The most common usage of FixupPrecode is for method fixups in NGen images.
- ThisPtrRetBufPrecode - .. is used to switch a return buffer and the this pointer for open instance delegates returning valuetypes. It is used to convert the calling convention of
MyValueType Bar(Foo x)to the calling convention ofMyValueType Foo::Bar(). - NDirectImportPrecode (a.k.a P/Invoke) - .. is used for lazy binding of unmanaged P/Invoke targets. This precode is for convenience and to reduce amount of platform specific plumbing.
Finally, to give you an idea of some real-world scenarios for ‘precode’ stubs, take a look at this comment from the DoesSlotCallPrestub(..) method (AMD64):
// AMD64 has the following possible sequences for prestub logic:
// 1. slot -> temporary entrypoint -> prestub
// 2. slot -> precode -> prestub
// 3. slot -> precode -> jumprel64 (jump stub) -> prestub
// 4. slot -> precode -> jumprel64 (NGEN case) -> prestub
‘Just-in-time’ (JIT) and ‘Tiered’ Compilation
However, another piece of functionality that ‘precodes’ provide is related to ‘just-in-time’ (JIT) compilation, again from the BotR page:
Temporary entry points: Methods must provide entry points before they are jitted so that jitted code has an address to call them. These temporary entry points are provided by precode. They are a specific form of stub wrappers.
This technique is a lazy approach to jitting, which provides a performance optimization in both space and time. Otherwise, the transitive closure of a method would need to be jitted before it was executed. This would be a waste, since only the dependencies of taken code branches (e.g. if statement) require jitting.
Each temporary entry point is much smaller than a typical method body. They need to be small since there are a lot of them, even at the cost of performance. The temporary entry points are executed just once before the actual code for the method is generated.
So these ‘temporary entry points’ provide something concrete that can be referenced before a method has been JITted. They then trigger the JIT-compilation which does the job of generating the native code for a method. The entire process looks like this (dotted lines represent a pointer indirection, solid lines are a ‘control transfer’ e.g. a jmp/call assembly instruction):
Before JITing

Here we see the ‘temporary entry point’ pointing to the ‘fixup precode’, which ultimately calls into the PrestubWorker() function here.
After JIting

Once the method has been JITted, we can see that the PrestubWorker is now out of the picture and instead we have the native code for the function. In addition, there is now a ‘stable entry point’ that can be used by any other code that wants to execute the function. Also, we can see that the ‘fixup precode’ has been ‘backpatched’ to also point at the ‘native code’. For an idea of how this ‘back-patching’ works, see the StubPrecode ::SetTargetInterlocked(..) method here (ARM64).
After JIting - Tiered Compilation

However, there is also another ‘after’ scenario, now that .NET Core has ‘Tiered Compilation’. Here we see that the ‘stable entry point’ still goes via the ‘fixup precode’, it doesn’t directly call into the ‘native code’. This is because ‘tiered compilation’ counts how many times a method is called and once it decides the method is ‘hot’, it re-compiles a more optimised version that will give better performance. This ‘call counting’ takes place in this code in MethodDesc::DoPrestub(..) which calls into CodeVersionManager::PublishNonJumpStampVersionableCodeIfNecessary(..) here and then if shouldCountCalls is true, it ends up calling CallCounter::OnMethodCodeVersionCalledSubsequently(..) here.
What’s been interesting to watch during the development of ‘tiered compilation’ is that (not surprisingly) there has been a significant amount of work to ensure that the extra level of indirection doesn’t make the entire process slower, for instance see Patch vtable slots and similar when tiering is enabled #21292.
Like all the other stubs, ‘precodes’ have different versions for different CPU architectures. As a reference, the list below contains links to all of them:
Precodes(a.k.a ‘Precode Fixup Thunk’):- x86 in /vm/i386/asmhelpers.S
- x64 in /vm/amd64/AsmHelpers.asm
- ARM in /vm/arm/asmhelpers.S
- ARM64 in /vm/arm64/asmhelpers.asm
ThePreStub:- x86 in /vm/i386/asmhelpers.S
- x64 in /vm/amd64/ThePreStubAMD64.asm
- ARM in /vm/arm/asmhelpers.S
- ARM64 in /vm/arm64/asmhelpers.asm
PreStubWorker(..)in /vm/prestub.cppMethodDesc::DoPrestub(..)hereMethodDesc::DoBackpatch(..)here
Finally, for even more information on the JITing process, see:
- .NET Just in Time Compilation and Warming up Your System
- Writing a Managed JIT in C# with CoreCLR
- .NET Internals and Native Compiling
- .NET Internals and Code Injection
- Intercepting .NET / CLR Functions (in Russian, Google Translate version)
Stubs-as-IL
‘Stubs as IL’ actually describes several types of individual stubs, but what they all have in common is they’re generated from ‘Intermediate Language’ (IL) which is then compiled by the JIT, in exactly the same way it handles the code we write (after it’s first been compiled from C#/F#/VB.NET into IL by another compiler).
This makes sense, it’s far easier to write the IL once and then have the JIT worry about compiling it for different CPU architectures, rather than having to write raw assembly each time (for x86/x64/arm/etc). However all stubs were hand-written assembly in .NET Framework 1.0:
What you have described is how it actually works. The only difference is that the shuffle thunk is hand-emitted in assembly and not generated by the JIT for historic reasons. All stubs (including all interop stubs) were hand-emitted like this in .NET Framework 1.0. Starting with .NET Framework 2.0, we have been converting the stubs to be generated by the JIT (the runtime generates IL for the stub, and then the JIT compiles the IL as regular method). The shuffle thunk is one of the few remaining ones not converted yet. Also, we have the IL path on some platforms but not others -
FEATURE_STUBS_AS_ILis related to it.
In the CoreCLR source code, ‘stubs as IL’ are controlled by the feature flag FEATURE_STUBS_AS_IL, with the following additional flags for each specific type:
StubsAsILArrayStubAsILMulticastStubAsIL
On Windows only some features are implemented with IL stubs, see this code, e.g. ‘ArrayStubAsIL’ is disabled on ‘x86’, but enabled elsewhere.
<PropertyGroup Condition="'$(TargetsWindows)' == 'true'">
<FeatureArrayStubAsIL Condition="'$(Platform)' != 'x86'">true</FeatureArrayStubAsIL>
<FeatureMulticastStubAsIL Condition="'$(Platform)' != 'x86'">true</FeatureMulticastStubAsIL>
<FeatureStubsAsIL Condition="'$(Platform)' == 'arm64'">true</FeatureStubsAsIL>
...
</PropertyGroup>
On Unix they are all done in IL, regardless of CPU Arch, as this code shows:
<PropertyGroup Condition="'$(TargetsUnix)' == 'true'">
...
<FeatureArrayStubAsIL>true</FeatureArrayStubAsIL>
<FeatureMulticastStubAsIL>true</FeatureMulticastStubAsIL>
<FeatureStubsAsIL>true</FeatureStubsAsIL>
</PropertyGroup>
Finally, here’s the complete list of stubs that can be implemented in IL from /vm/ilstubresolver.h:
enum ILStubType
{
Unassigned = 0,
CLRToNativeInteropStub,
CLRToCOMInteropStub,
CLRToWinRTInteropStub,
NativeToCLRInteropStub,
COMToCLRInteropStub,
WinRTToCLRInteropStub,
#ifdef FEATURE_ARRAYSTUB_AS_IL
ArrayOpStub,
#endif
#ifdef FEATURE_MULTICASTSTUB_AS_IL
MulticastDelegateStub,
#endif
#ifdef FEATURE_STUBS_AS_IL
SecureDelegateStub,
UnboxingILStub,
InstantiatingStub,
#endif
};
But the usage of IL stubs has grown over time and it seems that they are the preferred mechanism where possible as they’re easier to write and debug. See [x86/Linux] Enable FEATURE_ARRAYSTUB_AS_IL, Switch multicast delegate stub on Windows x64 to use stubs-as-il and Fix GenerateShuffleArray to support cyclic shuffles #26169 (comment) for more information.
P/Invoke, Reverse P/Invoke and ‘calli’
All these stubs have one thing in common, they allow a transition between ‘managed’ and ‘un-managed’ (or native) code. To make this safe and to preserve the guarantees that the .NET runtime provides, stubs are used every time the transition is made.
This entire process is outlined in great detail in the BotR page CLR ABI - PInvokes, from the ‘Per-call-site PInvoke work’ section:
- For direct calls, the JITed code sets
InlinedCallFrame->m_pDatumto the MethodDesc of the call target.
- For JIT64, indirect calls within IL stubs sets it to the secret parameter (this seems redundant, but it might have changed since the per-frame initialization?).
- For JIT32 (ARM) indirect calls, it sets this member to the size of the pushed arguments, according to the comments. The implementation however always passed 0.
- For JIT64/AMD64 only: Next for non-IL stubs, the InlinedCallFrame is ‘pushed’ by setting
Thread->m_pFrameto point to the InlinedCallFrame (recall that the per-frame initialization already setInlinedCallFrame->m_pNextto point to the previous top). For IL stubs this step is accomplished in the per-frame initialization.- The Frame is made active by setting
InlinedCallFrame->m_pCallerReturnAddress.- The code then toggles the GC mode by setting
Thread->m_fPreemptiveGCDisabled = 0.- Starting now, no GC pointers may be live in registers. RyuJit LSRA meets this requirement by adding special refPositon
RefTypeKillGCRefsbefore unmanaged calls and special helpers.- Then comes the actual call/PInvoke.
- The GC mode is set back by setting
Thread->m_fPreemptiveGCDisabled = 1.- Then we check to see if
g_TrapReturningThreadsis set (non-zero). If it is, we callCORINFO_HELP_STOP_FOR_GC.
- For ARM, this helper call preserves the return register(s):
R0,R1,S0, andD0.- For AMD64, the generated code must manually preserve the return value of the PInvoke by moving it to a non-volatile register or a stack location.
- Starting now, GC pointers may once again be live in registers.
- Clear the
InlinedCallFrame->m_pCallerReturnAddressback to 0.- For JIT64/AMD64 only: For non-IL stubs ‘pop’ the Frame chain by resetting
Thread->m_pFrameback toInlinedCallFrame.m_pNext.Saving/restoring all the non-volatile registers helps by preventing any registers that are unused in the current frame from accidentally having a live GC pointer value from a parent frame. The argument and return registers are ‘safe’ because they cannot be GC refs. Any refs should have been pinned elsewhere and instead passed as native pointers.
For IL stubs, the Frame chain isn’t popped at the call site, so instead it must be popped right before the epilog and right before any jmp calls. It looks like we do not support tail calls from PInvoke IL stubs?
As you can see, quite a bit of the work is to keep the Garbage Collector (GC) happy. This makes sense because once execution moves into un-managed/native code the .NET runtime has no control over what’s happening, so it needs to ensure that the GC doesn’t clean up or move around objects that are being used in the native code. It achives this by constraining what the GC can do (on the current thread) from the time execution moves into un-managed code and keeps that in place until it returns back to the mamanged side.
On top of that, there needs to be support for allowing ‘stack walking’ or ‘unwinding, to allowing debugging and produce meaningful stack traces. This is done by setting up frames that are put in place when control transitions from managed -> un-managed, before being removed (‘popped’) when transitioning back. Here’s a list of the different scenarios that are covered, from /vm/frames.h:
This is the list of Interop stubs & transition helpers with information
regarding what (if any) Frame they used and where they were set up:
P/Invoke:
JIT inlined: The code to call the method is inlined into the caller by the JIT.
InlinedCallFrame is erected by the JITted code.
Requires marshaling: The stub does not erect any frames explicitly but contains
an unmanaged CALLI which turns it into the JIT inlined case.
Delegate over a native function pointer:
The same as P/Invoke but the raw JIT inlined case is not present (the call always
goes through an IL stub).
Calli:
The same as P/Invoke.
PInvokeCalliFrame is erected in stub generated by GenerateGetStubForPInvokeCalli
before calling to GetILStubForCalli which generates the IL stub. This happens only
the first time a call via the corresponding VASigCookie is made.
ClrToCom:
Late-bound or eventing: The stub is generated by GenerateGenericComplusWorker
(x86) or exists statically as GenericComPlusCallStub[RetBuffArg] (64-bit),
and it erects a ComPlusMethodFrame frame.
Early-bound: The stub does not erect any frames explicitly but contains an
unmanaged CALLI which turns it into the JIT inlined case.
ComToClr:
Normal stub:
Interpreted: The stub is generated by ComCall::CreateGenericComCallStub
(in ComToClrCall.cpp) and it erects a ComMethodFrame frame.
Prestub:
The prestub is ComCallPreStub (in ComCallableWrapper.cpp) and it erects a ComPrestubMethodFrame frame.
Reverse P/Invoke (used for C++ exports & fixups as well as delegates
obtained from function pointers):
Normal stub:
x86: The stub is generated by UMEntryThunk::CompileUMThunkWorker
(in DllImportCallback.cpp) and it is frameless. It calls directly
the managed target or to IL stub if marshaling is required.
non-x86: The stub exists statically as UMThunkStub and calls to IL stub.
Prestub:
The prestub is generated by GenerateUMThunkPrestub (x86) or exists statically
as TheUMEntryPrestub (64-bit), and it erects an UMThkCallFrame frame.
Reverse P/Invoke AppDomain selector stub:
The asm helper is IJWNOADThunkJumpTarget (in asmhelpers.asm) and it is frameless.
The P/Invoke IL stubs are wired up in the MethodDesc::DoPrestub(..) method (note that P/Invoke is also known as ‘NDirect’), in addition they are also created here when being used for ‘COM Interop’. That code then calls into GetStubForInteropMethod(..) in /vm/dllimport.cpp, before branching off to handle each case:
- P/Invoke calls into
NDirect::GetStubForILStub(..)here - Reverse P/Invoke calls into another overload of
NDirect::GetStubForILStub(..)here - COM Interop goes to
ComPlusCall::GetStubForILStub(..)here in /vm/clrtocomcall.cpp - EE implemented methods end up in
COMDelegate::GetStubForILStub(..)here (for more info onEEImplmethods see ‘Kinds of MethodDescs’)
There are also hand-written assembly stubs for the differents scenarios, such as JIT_PInvokeBegin, JIT_PInvokeEnd and VarargPInvokeStub, these can be seen in the files below:
- x64 in /vm/amd64/PInvokeStubs.asm
- x86 in /vm/i386/PInvokeStubs.asm
- ARM in /vm/arm/PInvokeStubs.asm
- ARM64 in /vm/arm64/PInvokeStubs.asm
As an example, calli method calls (see OpCodes.Calli) end up in GenericPInvokeCalliHelper, which has a nice bit of ASCII art in the i386 version:
// stack layout at this point:
//
// | ... |
// | stack arguments | ESP + 16
// +----------------------+
// | VASigCookie* | ESP + 12
// +----------------------+
// | return address | ESP + 8
// +----------------------+
// | CALLI target address | ESP + 4
// +----------------------+
// | stub entry point | ESP + 0
// ------------------------
However, all these stubs can have an adverse impact on start-up time, see Large numbers of Pinvoke stubs created on startup for example. This impact has been mitigated by compiling the stubs ‘Ahead-of-Time’ (AOT) and storing them in the ‘Ready-to-Run’ images (replacement format for NGEN (Native Image Generator)). From R2R ilstubs:
IL stub generation for interop takes measurable time at startup, and it is possible to generate some of them in an ahead of time
This change introduces ahead of time R2R compilation of IL stubs
Related work was done in Enable R2R compilation/inlining of PInvoke stubs where no marshalling is required and PInvoke stubs for Unix platforms (‘Enables inlining of PInvoke stubs for Unix platforms’).
Finally, for even more information on the issues involved, see:
- Better diagnostic for collected delegate #15465
- Fill freed loader heap chunk with non-zero value #12731
- [Arm64] Implement Poison() #13125
- Collected delegate diagnostic #15809
- AdvancedDLSupport:
- Delegate-based C# P/Invoke alternative - compatible with all platforms and runtimes.
- Also see ‘The Developer Documentation’ for the project.
Marshalling
However, dealing with the ‘managed’ to ‘un-managed’ transition is only one part of the story. The other is that there are also stubs created to deal with the ‘marshalling’ of arguments between the 2 sides. This process of ‘Interop Marshalling’ is explained nicely in the Microsoft docs:
Interop marshaling governs how data is passed in method arguments and return values between managed and unmanaged memory during calls. Interop marshaling is a run-time activity performed by the common language runtime’s marshaling service.
Most data types have common representations in both managed and unmanaged memory. The interop marshaler handles these types for you. Other types can be ambiguous or not represented at all in managed memory.
Like many stubs in the CLR, the marshalling stubs have evolved over time. As we can read in the excellent post Improvements to Interop Marshaling in V4: IL Stubs Everywhere:
History The 1.0 and 1.1 versions of the CLR had several different techniques for creating and executing these stubs that were each designed for marshaling different types of signatures. These techniques ranged from directly generated x86 assembly instructions for simple signatures to generating specialized ML (an internal marshaling language) and running them through an internal interpreter for the most complicated signatures. This system worked well enough – although not without difficulties – in 1.0 and 1.1 but presented us with a serious maintenance problem when 2.0, and its support for multiple processor architectures, came around.
That’s right, there was an internal interpreter built into early version of the .NET CLR that had the job of running the ‘marshalling language’ (ML) code!
However, it then goes on to explain why this process wasn’t sustainable:
We realized early in the process of adding 64 bit support to 2.0 that this approach was not sustainable across multiple architectures. Had we continued with the same strategy we would have had to create parallel marshaling infrastructures for each new architecture we supported (remember in 2.0 we introduced support for both x64 and IA64) which would, in addition to the initial cost, at least triple the cost of every new marshaling feature or bug fix. We needed one marshaling stub technology that would work on multiple processor architectures and could be efficiently executed on each one: enter IL stubs.
The solution was to implement all stubs using ‘Intermediate Language’ (IL) that is CPU-agnostic. Then the JIT-compiler is used to convert the IL into machine code for each CPU architecture, which makes sense because it’s exactly what the JIT is good at. Also worth noting is that this work still continues today, for instance see Implement struct marshalling via IL Stubs instead of via FieldMarshalers #26340.
Finally, there is a really nice investigation into the whole process in PInvoke: beyond the magic (also Compile time marshalling). What’s also nice is that you can use PerfView to see the stubs that the runtime generates.
Generics
It is reasonably well known that generics in .NET use ‘code sharing’ to save space. That is, given a generic method such as public void Insert<T>(..), one method body of ‘native code’ will be created and shared by the instantiated types of Insert<Foo>(..) and Insert<Bar>(..) (assumning that Foo and Bar are references types), but different versions will be created for Insert<int>(..) and Insert<double>(..) (as int/double are value types). This is possible, for the reasons outlined by Jon Skeet in a StackOverflow question:
.. consider what the CLR needs to know about a type. It includes:
- The size of a value of that type (i.e. if you have a variable of some type, how much space will that memory need?)
- How to treat the value in terms of garbage collection: is it a reference to an object, or a value which may in turn contain other references?
For all reference types, the answers to these questions are the same. The size is just the size of a pointer, and the value is always just a reference (so if the variable is considered a root, the GC needs to recursively descend into it).
For value types, the answers can vary significantly.
But, this poses a problem. What about if the ‘shared’ method needs to do something specific for each type, like call typeof(T)?
This whole issue is explained in these 2 great posts, which I really recommend you take the time to read:
I’m not going to repeat what they cover here, except to say that (not surprisingly) ‘stubs’ are used to solve this issue, in conjunction with a ‘hidden’ parameter. These stubs are known as ‘instantiating’ stubs and we can find out more about them in this comment:
Instantiating Stubs - Return TRUE if this is this a special stub used to implement an instantiated generic method or per-instantiation static method. The action of an instantiating stub is - pass on a
MethodTableorInstantiatedMethodDescextra argument to shared code
The different scenarios are handled in MakeInstantiatingStubWorker(..) in /vm/prestub.cpp, you can see the check for HasMethodInstantiation and the fall-back to a ‘per-instantiation static method’:
// It's an instantiated generic method
// Fetch the shared code associated with this instantiation
pSharedMD = pMD->GetWrappedMethodDesc();
_ASSERTE(pSharedMD != NULL && pSharedMD != pMD);
if (pMD->HasMethodInstantiation())
{
extraArg = pMD;
}
else
{
// It's a per-instantiation static method
extraArg = pMD->GetMethodTable();
}
Stub *pstub = NULL;
#ifdef FEATURE_STUBS_AS_IL
pstub = CreateInstantiatingILStub(pSharedMD, extraArg);
#else
CPUSTUBLINKER sl;
_ASSERTE(pSharedMD != NULL && pSharedMD != pMD);
sl.EmitInstantiatingMethodStub(pSharedMD, extraArg);
pstub = sl.Link(pMD->GetLoaderAllocator()->GetStubHeap());
#endif
As a reminder, FEATURE_STUBS_AS_IL is defined for all Unix versions of the CoreCLR, but on Windows it’s only used with ARM64.
- When
FEATURE_STUBS_AS_ILis defined, the code calls intoCreateInstantiatingILStub(..)here. To get an overview of what it’s doing, we can take a look at the steps called-out in the code comments: - When
FEATURE_STUBS_AS_ILis note defined, per CPU/OS versions ofEmitInstantiatingMethodStub(..)are used, they exist for:- i386 in /vm/i386/stublinkerx86.cpp
- ARM in /vm/arm/stubs.cpp
In the last case, (EmitInstantiatingMethodStub(..) on ARM), the stub shares code with the instantiating version of the unboxing stub, so the heavy-lifting is done in StubLinkerCPU::ThumbEmitCallWithGenericInstantiationParameter(..) here. This method is over 400 lines for fairly complex code, althrough there is also a nice piece of ASCII art (for info on why this ‘complex’ case is needed see this comment):
// Complex case where we need to emit a new stack frame and copy the arguments.
// Calculate the size of the new stack frame:
//
// +------------+
// SP -> | | <-- Space for helper arg, if isRelative is true
// +------------+
// | | <-+
// : : | Outgoing arguments
// | | <-+
// +------------+
// | Padding | <-- Optional, maybe required so that SP is 64-bit aligned
// +------------+
// | GS Cookie |
// +------------+
// +-> | vtable ptr |
// | +------------+
// | | m_Next |
// | +------------+
// | | R4 | <-+
// Stub | +------------+ |
// Helper | : : |
// Frame | +------------+ | Callee saved registers
// | | R11 | |
// | +------------+ |
// | | LR/RetAddr | <-+
// | +------------+
// | | R0 | <-+
// | +------------+ |
// | : : | Argument registers
// | +------------+ |
// +-> | R3 | <-+
// +------------+
// Old SP -> | |
//
Delegates
Delegates in .NET provide a nice abstraction over the top of a function call, from Delegates (C# Programming Guide):
A delegate is a type that represents references to methods with a particular parameter list and return type. When you instantiate a delegate, you can associate its instance with any method with a compatible signature and return type. You can invoke (or call) the method through the delegate instance.
But under the hood there is quite a bit going on, for the full story take a look at How do .NET delegates work?, but in summary, there are several different types of delegates, as shown in this table from /vm/comdelegate.cpp:
// DELEGATE KINDS TABLE
//
// _target _methodPtr _methodPtrAux _invocationList _invocationCount
//
// 1- Instance closed 'this' ptr target method null null 0
// 2- Instance open non-virt delegate shuffle thunk target method null 0
// 3- Instance open virtual delegate Virtual-stub dispatch method id null 0
// 4- Static closed first arg target method null null 0
// 5- Static closed (special sig) delegate specialSig thunk target method first arg 0
// 6- Static opened delegate shuffle thunk target method null 0
// 7- Secure delegate call thunk MethodDesc (frame) target delegate creator assembly
//
// Delegate invoke arg count == target method arg count - 2, 3, 6
// Delegate invoke arg count == 1 + target method arg count - 1, 4, 5
//
// 1, 4 - MulticastDelegate.ctor1 (simply assign _target and _methodPtr)
// 5 - MulticastDelegate.ctor2 (see table, takes 3 args)
// 2, 6 - MulticastDelegate.ctor3 (take shuffle thunk)
// 3 - MulticastDelegate.ctor4 (take shuffle thunk, retrieve MethodDesc) ???
//
// 7 - Needs special handling
The difference between Open Delegates vs. Closed Delegates is nicely illustrated in this code sample from the linked post:
Func<string> closed = new Func<string>("a".ToUpperInvariant);
Func<string, string> open = (Func<string, string>)
Delegate.CreateDelegate(
typeof(Func<string, string>),
typeof(string).GetMethod("ToUpperInvariant")
);
closed(); //Returns "A"
open("abc"); //Returns "ABC"
Stubs are used in several scenarios, including the intruiging named ‘shuffle thunk’ whose job it is to literally shuffle arguments around! In the simplest case, this process looks a bit like the following:
Delegate Call: [delegateThisPtr, arg1, arg2, ...]
Method Call: [targetThisPtr, arg1, arg2, ...]
So when you invoke a delegate, the Invoke(..) method (generated by CLR), expects a ‘this’ pointer of the delegate object itself. However when the target method is called (i.e. the method the delagate ‘wraps’), the ‘this’ pointer needs to be the one for the type/class that the target method exists in, hence all the swapping/shuffling.
Of couse things get more complicated when you deal with static methods (no ‘this’ pointer) and different CPU calling conventions, as this answer to the question ‘What in the world is a shuffle thunk cache?’ explains:
When you use a delegate to call a method, the JIT doesn’t know at the time it generates the code what the delegate points to. It can e.g. be a member method or a static method. So the JIT generates arguments to registers and stack based on the signature of the delegate and the call then doesn’t call the target method directly, but a shuffle thunk instead. This thunk is generated based on the caller side signature and the real target method signature and shuffles the arguments in registers and on stack to correspond to the target calling convention. So if it needs to add “this” pointer into the first argument register, it needs to move the first argument register to the second, the second to the third and the last to the stack (obviously in the right order so that nothing gets overwritten). And e.g. Unix amd64 calling convention makes it even more interesting when there are arguments that are structs that can be passed in multiple registers.
Singlecast Delegates
‘Singlecast’ delegates (as opposed to the ‘multicast’ variants) are the most common scenario and so they’re written as optimised ‘stubs’, starting in:
MethodDesc::DoPrestub(..)here, specifically whenIsEEImpl()is true which calls intoCOMDelegate::GetInvokeMethodStub(..)here, that then callsCOMDelegate::TheDelegateInvokeStub(..)here- If
FEATURE_STUBS_AS_ILis not defined, it calls intoEmitDelegateInvoke()in /vm/i386/stublinkerx86.cpp (for x86) - If
FEATURE_STUBS_AS_ILis defined, a per-CPU/OS version ofSinglecastDelegateInvokeStubis wired up:- Windows
- AMD64 /vm/amd64/AsmHelpers.asm
- ARM /vm/arm/asmhelpers.asm
- ARM64 /vm/arm64/asmhelpers.asm
- Unix
- i386 /vm/i386/asmhelpers.S
- AMD64 /vm/amd64/unixasmhelpers.S
- ARM /vm/arm/asmhelpers.S
- ARM64 /vm/arm64/asmhelpers.S
- Windows
- If
For example, this is the AMD64 (Windows) version of SinglecastDelegateInvokeStub:
LEAF_ENTRY SinglecastDelegateInvokeStub, _TEXT
test rcx, rcx
jz NullObject
mov rax, [rcx + OFFSETOF__DelegateObject___methodPtr]
mov rcx, [rcx + OFFSETOF__DelegateObject___target] ; replace "this" pointer
jmp rax
NullObject:
mov rcx, CORINFO_NullReferenceException_ASM
jmp JIT_InternalThrow
LEAF_END SinglecastDelegateInvokeStub, _TEXT
As you can see, it reaches into the internals of the DelegateObject, pulls out the values in the methodPtr and target fields and puts them into the the rax and rcx registers.
Shuffle Thunks
Finally, let’s look at ‘shuffle thunks’ in more detail (cases 2, 3, 6 from the table above).
- There are created in several places in the CoreCLR source, which all call into
COMDelegate::SetupShuffleThunk(..)here COMDelegate::SetupShuffleThunk(..)then callsGenerateShuffleArray(..)here- Followed by a call to
StubCacheBase::Canonicalize(..)here, that ends up inShuffleThunkCache::CompileStub(..)here - This ends up calls the CPU-specific method
EmitShuffleThunk(..):- src/vm/i386 (also does AMD64 and UNIX_AMD64_ABI)
- src/vm/arm
- src/vm/arm64
Note how the stubs are cached in the ShuffleThunkCache where possible. This is because the thunks don’t have to be unique per method they can be shared across multiple methods as long as the signatures are compatible.
However, these stubs are not straight-forward and sometimes they go wrong, for instance Infinite loop in GenerateShuffleArray on unix64 #26054, fixed in PR #26169. Also see Corrupted struct passed to delegate constructed via reflection #16833 and Fix shuffling thunk for Unix AMD64 #16904 for more examples.
To give a flavour of what they need to do, here’s the code of the ARM64 version, which is by far the simplest one!! If you want to understand the full complexities, take a look at the ARM version which is 182 LOC or the x86 one at 281 LOC!!
// Emits code to adjust arguments for static delegate target.
VOID StubLinkerCPU::EmitShuffleThunk(ShuffleEntry *pShuffleEntryArray)
{
// On entry x0 holds the delegate instance. Look up the real target address stored in the MethodPtrAux
// field and save it in x16(ip). Tailcall to the target method after re-arranging the arguments
// ldr x16, [x0, #offsetof(DelegateObject, _methodPtrAux)]
EmitLoadStoreRegImm(eLOAD, IntReg(16), IntReg(0), DelegateObject::GetOffsetOfMethodPtrAux());
//add x11, x0, DelegateObject::GetOffsetOfMethodPtrAux() - load the indirection cell into x11 used by ResolveWorkerAsmStub
EmitAddImm(IntReg(11), IntReg(0), DelegateObject::GetOffsetOfMethodPtrAux());
for (ShuffleEntry* pEntry = pShuffleEntryArray; pEntry->srcofs != ShuffleEntry::SENTINEL; pEntry++)
{
if (pEntry->srcofs & ShuffleEntry::REGMASK)
{
// If source is present in register then destination must also be a register
_ASSERTE(pEntry->dstofs & ShuffleEntry::REGMASK);
EmitMovReg(IntReg(pEntry->dstofs & ShuffleEntry::OFSMASK), IntReg(pEntry->srcofs & ShuffleEntry::OFSMASK));
}
else if (pEntry->dstofs & ShuffleEntry::REGMASK)
{
// source must be on the stack
_ASSERTE(!(pEntry->srcofs & ShuffleEntry::REGMASK));
EmitLoadStoreRegImm(eLOAD, IntReg(pEntry->dstofs & ShuffleEntry::OFSMASK), RegSp, pEntry->srcofs * sizeof(void*));
}
else
{
// source must be on the stack
_ASSERTE(!(pEntry->srcofs & ShuffleEntry::REGMASK));
// dest must be on the stack
_ASSERTE(!(pEntry->dstofs & ShuffleEntry::REGMASK));
EmitLoadStoreRegImm(eLOAD, IntReg(9), RegSp, pEntry->srcofs * sizeof(void*));
EmitLoadStoreRegImm(eSTORE, IntReg(9), RegSp, pEntry->dstofs * sizeof(void*));
}
}
// Tailcall to target
// br x16
EmitJumpRegister(IntReg(16));
}
Unboxing
I’ve written about this type of ‘stub’ before in A look at the internals of ‘boxing’ in the CLR, but in summary the unboxing stub needs to handle steps 2) and 3) from the diagram below:
1. MyStruct: [0x05 0x00 0x00 0x00]
| Object Header | MethodTable | MyStruct |
2. MyStruct (Boxed): [0x40 0x5b 0x6f 0x6f 0xfe 0x7 0x0 0x0 0x5 0x0 0x0 0x0]
^
object 'this' pointer |
| Object Header | MethodTable | MyStruct |
3. MyStruct (Boxed): [0x40 0x5b 0x6f 0x6f 0xfe 0x7 0x0 0x0 0x5 0x0 0x0 0x0]
^
adjusted 'this' pointer |
Key to the diagram
- Original
struct, on the stack - The
structbeing boxed into anobjectthat lives on the heap - Adjustment made to this pointer so
MyStruct::ToString()will work
These stubs make is possible for ‘value types’ (structs) to override methods from System.Object, such as ToString() and GetHashCode(). The fix-up is needed because structs don’t have an ‘object header’, but when they’re boxed into an Object they do. So the stub has the job of moving or adjusting the ‘this’ pointer so that the code in the ToString() method can work the same, regardless of whether it’s operating on a regular ‘struct’ or one that’s been boxed into an ‘object.
The unboxing stubs are created in MethodDesc::DoPrestub(..) here, which in turn calls into MakeUnboxingStubWorker(..) here
- when
FEATURE_STUBS_AS_ILis disabled it then callsEmitUnboxMethodStub(..)to create the stub, there are per-CPU versions: - when
FEATURE_STUBS_AS_ILis enabled is instead calls intoCreateUnboxingILStubForSharedGenericValueTypeMethods(..)here
For more information on some of the internal details of unboxing stubs and how they interact with ‘generic instantiations’ see this informative comment and one in the code for MethodDesc::FindOrCreateAssociatedMethodDesc(..) here.
Arrays
As discussed at the beginning, the method bodies for arrays is provided by the runtime, that is the array access methods, ‘get’ and ‘set’, that allow var a = myArray[5] and myArray[7] = 5 to work. Not surprisingly, these are done as stubs to allow them to be as small and efficient as possible.
Here is the flow for wiring up ‘array stubs’. It all starts up in MethodDesc::DoPrestub(..) here:
- If
FEATURE_ARRAYSTUB_AS_ILis defined (see ‘Stubs-as-IL’), it happens inGenerateArrayOpStub(ArrayMethodDesc* pMD)here - When
FEATURE_ARRAYSTUB_AS_ILisn’t defined, happens in another version ofGenerateArrayOpStub(ArrayMethodDesc* pMD)lower down- Then
void GenerateArrayOpScript(..)here - Followed by a call to
StubCacheBase::Canonicalize(..)here, that ends up inArrayStubCache::CompileStub(..)here. - Eventually, we end up in
StubLinkerCPU::EmitArrayOpStub(..)here, which does the heavy lifting (despite being under ‘\src\vm\i386' seems to support x86 and AMD64?)
- Then
I’m not going to include the code for the ‘stub-as-IL’ (ArrayOpLinker::EmitStub()) or the assembly code (StubLinkerCPU::EmitArrayOpStub(..)) versions of the array stubs because they’re both 100’s of lines long, dealing with type and bounds checking, computing address, multi-dimensional arrays and mode. But to give an idea of the complexities, take a look at this comment from StubLinkerCPU::EmitArrayOpStub(..) here:
// Register usage
//
// x86 AMD64
// Inputs:
// managed array THIS_kREG (ecx) THIS_kREG (rcx)
// index 0 edx rdx
// index 1/value <stack> r8
// index 2/value <stack> r9
// expected element type for LOADADDR eax rax rdx
// Working registers:
// total (accumulates unscaled offset) edi r10
// factor (accumulates the slice factor) esi r11
Finally, these stubs are still being improved, for example see Use unsigned index extension in muldi-dimensional array stubs.
Tail Calls
The .NET runtime provides a nice optimisation when doing ‘tail calls’, that (amoung other things) will prevent StackoverflowExceptions in recursive scenarios. For more on why these tail call optimisations are useful and how they work, take a look at:
- Demystifying Tail Call Optimization
- Tail call optimization
- Tail Recursion And Trampolining In C#
- Enter, Leave, Tailcall Hooks Part 2: Tall tales of tail calls
- Tail call JIT conditions
In summary, a tail call optimisation allows the same stack frame to be re-used if in the caller, there is no work done after the function call to the callee (see Tail call JIT conditions (2007) for a more precise definition).
And why is this beneficial? From Tail Call Improvements in .NET Framework 4:
The primary reason for a tail call as an optimization is to improve data locality, memory usage, and cache usage. By doing a tail call the callee will use the same stack space as the caller. This reduces memory pressure. It marginally improves the cache because the same memory is reused for subsequent callers and thus can stay in the cache, rather than evicting some older cache line to make room for a new cache line.
To make this clear, the code below can benefit from the optimisation, because both functions return straight after calling each the other:
public static long Ping(int cnt, long val)
{
if (cnt-- == 0)
return val;
return Pong(cnt, val + cnt);
}
public static long Pong(int cnt, long val)
{
if (cnt-- == 0)
return val;
return Ping(cnt, val + cnt);
}
However, if the code was changed to the version below, the optimisation would no longer work because PingNotOptimised(..) does some extra work between calling Pong(..) and when it returns:
public static long PingNotOptimised(int cnt, long val)
{
if (cnt-- == 0)
return val;
var result = Pong(cnt, val + cnt);
result += 1; // prevents the Tail-call optimization
return result;
}
public static long Pong(int cnt, long val)
{
if (cnt-- == 0)
return val;
return PingNotOptimised(cnt, val + cnt);
}
You can see the difference in the code emitted by the JIT compiler for the different scenarios in SharpLab.
But where do the ‘tail call optimisation stubs’ come into play? Helpfully there is a tail call related design doc that explains, from ‘current way of handling tail-calls’:
Fast tail calls These are tail calls that are handled directly by the jitter and no runtime cooperation is needed. They are limited to cases where:
- Return value and call target arguments are all either primitive types, reference types, or valuetypes with a single primitive type or reference type fields
- The aligned size of call target arguments is less or equal to aligned size of caller arguments
So, the stubs aren’t always needed, sometimes the work can be done by the JIT, if there scenario is simple enough.
However for the more complex cases, a ‘helper’ stub is needed:
Tail calls using a helper Tail calls in cases where we cannot perform the call in a simple way are implemented using a tail call helper. Here is a rough description of how it works:
- For each tail call target, the jitter asks runtime to generate an assembler argument copying routine. This routine reads vararg list of arguments and places the arguments in their proper slots in the CONTEXT or on the stack. Together with the argument copying routine, the runtime also builds a list of offsets of references and byrefs for return value of reference type or structs returned in a hidden return buffer and for structs passed by ref. The gc layout data block is stored at the end of the argument copying thunk.
- At the time of the tail call, the caller generates a vararg list of all arguments of the tail called function and then calls
JIT_TailCallruntime function. It passes it the copying routine address, the target address and the vararg list of the arguments.- The
JIT_TailCallthen performs the following: …
To see the rest of the steps that JIT_TailCall takes you can read the design doc or if you’re really keen you can look at the code in /vm/jithelpers.cpp. Also, there’s a useful explanation of what it needs to handle in the JIT code, see here and here.
However, we’re just going to focus on the stubs, refered to as an ‘assembler argument copying routine’. Firstly, we can see that they have their own stub manager, TailCallStubManager, which is implemented here and allows the stubs to play nicely with the debugger. Also interesting to look at is the TailCallFrame here that is used to ensure that the ‘stack walker’ can work well with tail calls.
Now, onto the stubs themselves, the ‘copying routines’ are provided by the runtime via a call to CEEInfo::getTailCallCopyArgsThunk(..) in /vm/jitinterface.cpp. This in turn calls the CPU specific versions of CPUSTUBLINKER::CreateTailCallCopyArgsThunk(..):
These routines have the complex and hairy job of dealing with the CPU registers and calling conventions. They achieve this by dynamicially emitting assembly instructions, to create a function that looks like the following pseudo code (X86 version):
// size_t CopyArguments(va_list args, (RCX)
// CONTEXT *pCtx, (RDX)
// DWORD64 *pvStack, (R8)
// size_t cbStack) (R9)
// {
// if (pCtx != NULL) {
// foreach (arg in args) {
// copy into pCtx or pvStack
// }
// }
// return <size of stack needed>;
// }
In addition there is one other type of stub that is used. Known as the TailCallHelperStub, they also come in per-CPU versions:
Going forward, there are several limitations of to this approach of using per-CPU stubs, as the design doc explains:
- It is expensive to port to new platforms
- Parsing the vararg list is not possible to do in a portable way on Unix. Unlike on Windows, the list is not stored a linear sequence of the parameter data bytes in memory. va_list on Unix is an opaque data type, some of the parameters can be in registers and some in the memory.
- Generating the copying asm routine needs to be done for each target architecture / platform differently. And it is also very complex, error prone and impossible to do on platforms where code generation at runtime is not allowed.
- It is slower than it has to be
- The parameters are copied possibly twice - once from the vararg list to the stack and then one more time if there was not enough space in the caller’s stack frame.
RtlRestoreContextrestores all registers from theCONTEXTstructure, not just a subset of them that is really necessary for the functionality, so it results in another unnecessary memory accesses.- Stack walking over the stack frames of the tail calls requires runtime assistance.
Fortunately, it then goes into great depth discussing how a new approach could be implemented and how it would solve these issues. Even better, work has already started and we can follow along in Implement portable tailcall helpers #26418 (currently sitting at ‘31 of 55’ tasks completed, with over 50 files modified, it’s not a small job!).
Finally, for other PRs related to tail calls, see:
- Disable JIT_TailCall invocation on Unix #703
- JIT: enable implicit tail calls from inlined code #9405
- Full tailcall support on Unix #2556
Virtual Stub Dispatch (VSD)
I’ve saved the best for last, ‘Virtual Stub Dispatch’ or VSD is such an in-depth topic, that it an entire BotR page devoted to it!! From the introduction:
Virtual stub dispatching (VSD) is the technique of using stubs for virtual method invocations instead of the traditional virtual method table. In the past, interface dispatch required that interfaces had process-unique identifiers, and that every loaded interface was added to a global interface virtual table map. This requirement meant that all interfaces and all classes that implemented interfaces had to be restored at runtime in NGEN scenarios, causing significant startup working set increases. The motivation for stub dispatching was to eliminate much of the related working set, as well as distribute the remaining work throughout the lifetime of the process.
It then goes on to say:
Although it is possible for VSD to dispatch both virtual instance and interface method calls, it is currently used only for interface dispatch.
So despite having the work ‘virtual’ in the title, it’s not actually used for C# methods with the virtual modifier on them. However, if you look at the IL for interface methods you can see why they are also known as ‘virtual’.
Virtual Stub Dispatch is so complex, it actually has several different stub types, from /vm/virtualcallstub.h:
enum StubKind {
SK_UNKNOWN,
SK_LOOKUP, // Lookup Stubs are SLOW stubs that simply call into the runtime to do all work.
SK_DISPATCH, // Dispatch Stubs have a fast check for one type otherwise jumps to runtime. Works for monomorphic sites
SK_RESOLVE, // Resolve Stubs do a hash lookup before fallling back to the runtime. Works for polymorphic sites.
SK_VTABLECALL, // Stub that jumps to a target method using vtable-based indirections. Works for non-interface calls.
SK_BREAKPOINT
};
So there are the following types (these are links to the AMD64 versions, x86 versions are in /vm/i386/virtualcallstubcpu.hpp):
- Lookup Stubs:
// Virtual and interface call sites are initially setup to point at LookupStubs. This is because the runtime type of the <this> pointer is not yet known, so the target cannot be resolved.
- Dispatch Stubs:
// Monomorphic and mostly monomorphic call sites eventually point to DispatchStubs. A dispatch stub has an expected type (expectedMT), target address (target) and fail address (failure). If the calling frame does in fact have the <this> type be of the expected type, then control is transfered to the target address, the method implementation. If not, then control is transfered to the fail address, a fail stub (see below) where a polymorphic lookup is done to find the correct address to go to.- There’s also specific versions, DispatchStubShort and DispatchStubLong, see this comment for why they are both needed.
- Resolve Stubs:
// Polymorphic call sites and monomorphic calls that fail end up in a ResolverStub. There is only one resolver stub built for any given token, even though there may be many call sites that use that token and many distinct <this> types that are used in the calling call frames. A resolver stub actually has two entry points, one for polymorphic call sites and one for dispatch stubs that fail on their expectedMT test. There is a third part of the resolver stub that enters the ee when a decision should be made about changing the callsite.
- V-Table or Virtual Call Stubs
//These are jump stubs that perform a vtable-base virtual call. These stubs assume that an object is placed in the first argument register (this pointer). From there, the stub extracts the MethodTable pointer, followed by the vtable pointer, and finally jumps to the target method at a given slot in the vtable.
The below diagram shows the general control flow between these stubs
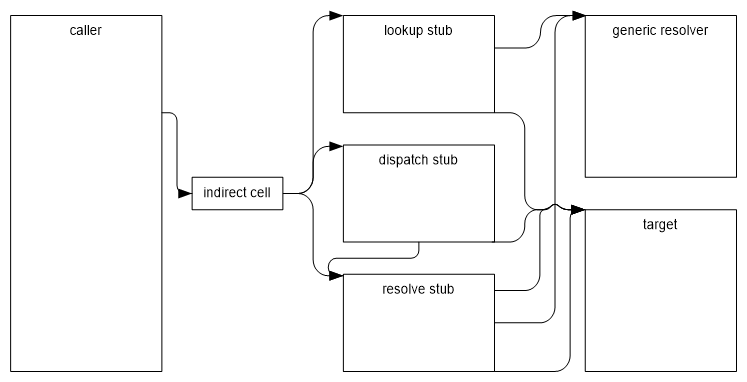
(Image from ‘Design of Virtual Stub Dispatch’)
Finally, if you want even more in-depth information see this comment.
However, these stubs come at a cost, which makes virtual method calls more expensive than direct ones. This is why de-virtualization is so important, i.e. the process of the .NET JIT detecting when a virtual call can instead be replaced by a direct one. There has been some work done in .NET Core to improve this, see Simple devirtualization #9230 which covers sealed classes/methods and when the object type is known exactly. However there is still more to be done, as shown in JIT: devirtualization next steps #9908, where ‘5 of 23’ tasks have been completed.
Other Types of Stubs
This post is already way too long, so I don’t intend to offer any analysis of the following stubs. Instead I’ve just included some links to more information so you can read up on any that interest you!
‘Jump’ stubs
- ‘Jump Stubs’ design doc
- Out-of-memory exception in a managed application that’s running on the 64-bit .NET Framework
‘Function Pointer’ stubs
- ‘Function Pointer’ Stubs, see /vm/fptrstubs.cpp and /vm/fptrstubs.h
// FuncPtrStubs contains stubs that is used by GetMultiCallableAddrOfCode() if the function has not been jitted. Using a stub decouples ldftn from the prestub, so prestub does not need to be backpatched. This stub is also used in other places which need a function pointer
‘Thread Hijacking’ stubs
From the BotR page on ‘Threading’:
- If fully interruptable, it is safe to perform a GC at any point, since the thread is, by definition, at a safe point. It is reasonable to leave the thread suspended at this point (because it’s safe) but various historical OS bugs prevent this from working, because the CONTEXT retrieved earlier may be corrupt). Instead, the thread’s instruction pointer is overwritten, redirecting it to a stub that will capture a more complete CONTEXT, leave cooperative mode, wait for the GC to complete, reenter cooperative mode, and restore the thread to its previous state.
- If partially-interruptable, the thread is, by definition, not at a safe point. However, the caller will be at a safe point (method transition). Using that knowledge, the CLR “hijacks” the top-most stack frame’s return address (physically overwrite that location on the stack) with a stub similar to the one used for fully-interruptable code. When the method returns, it will no longer return to its actual caller, but rather to the stub (the method may also perform a GC poll, inserted by the JIT, before that point, which will cause it to leave cooperative mode and undo the hijack).
Done with the OnHijackTripThread method in /vm/amd64/AsmHelpers.asm, which calls into OnHijackWorker(..) in /vm/threadsuspend.cpp.
‘NGEN Fixup’ stubs
From CLR Inside Out - The Performance Benefits of NGen (2006):
Throughput of NGen-compiled code is lower than that of JIT-compiled code primarily for one reason: cross-assembly references. In JIT-compiled code, cross-assembly references can be implemented as direct calls or jumps since the exact addresses of these references are known at run time. For statically compiled code, however, cross-assembly references need to go through a jump slot that gets populated with the correct address at run time by executing a method pre-stub. The method pre-stub ensures, among other things, that the native images for assemblies referenced by that method are loaded into memory before the method is executed. The pre-stub only needs to be executed the first time the method is called; it is short-circuited out for subsequent calls. However, every time the method is called, cross-assembly references do need to go through a level of indirection. This is principally what accounted for the 5-10 percent drop in throughput for NGen-compiled code when compared to JIT-compiled code.
Also see the ‘NGEN’ section of the ‘jump stub’ design doc.
Stubs in the Mono Runtime
Mono refers to ‘Stubs’ as ‘Trampolines’ and they’re widely used in the source code.
The Mono docs have an excellent page all about ‘Trampolines’, that lists the following types:
- JIT Trampolines
- Virtual Call Trampolines
- Jump Trampolines
- Class Init Trampolines
- Generic Class Init Trampoline
- RGCTX Lazy Fetch Trampolines
- AOT Trampolines
- Delegate Trampolines
- Monitor Enter/Exit Trampolines
Also the docs page on Generic Sharing has some good, in-depth information.
- Memory savings with magic trampolines in Mono
- Mono JIT Enhancements: Trampolines and Code Sharing
- Generics Improvements
- Generics Sharing in Mono
- The Trouble with Shared Generics
- IL2CPP Internals: Generic sharing implementation
- How-to trigger JIT compilation
Conclusion
So it turns out that ‘stubs’ are way more prevelant in the .NET Core Runtime that I imagined when I first started on this post. They are an interesting technique and they contain a fair amount of complexity. In addition, I only covered each stub in isolation, in reality many of them have to play nicely together, for instance imagine a delegate calling a virtual method that has generic type parameters and you can see that things start to get complex! (that scenario might contain 3 seperate stubs, although they are also shared where possible). If you were then to add array methods, P/Invoke marshalling and un-boxing to the mix, things get even more hairy and even more complex!
If anyone has read this far and wants a fun challenge, try and figure out what’s the most stubs you can force a single method call to go via! If you do, let me know in the comments or via twitter
Finally, by knowing where and when stubs are involved in our method calls, we can start to understand the overhead of each scenario. For instance, it explains why delegate method calls are a bit slower than calling a method directly and why ‘de-virtualization’ is so important. Having the JIT be able to perform extra analysis to determine that a virtual call can be converted into a direct one skips an entire level of indirection, for more on this see: