The CLR Thread Pool 'Thread Injection' Algorithm
13 Apr 2017 - 2095 wordsIf you’re near London at the end of April, I’ll be speaking at ProgSCon 2017 on Microsoft and Open-Source – A ‘Brave New World’. ProgSCon is 1-day conference, with talks covering an eclectic range of topics, you’ll learn lots!!
As part of a never-ending quest to explore the CoreCLR source code I stumbled across the intriguing titled ‘HillClimbing.cpp’ source file. This post explains what it does and why.
What is ‘Hill Climbing’
It turns out that ‘Hill Climbing’ is a general technique, from the Wikipedia page on the Hill Climbing Algorithm:
In computer science, hill climbing is a mathematical optimization technique which belongs to the family of local search. It is an iterative algorithm that starts with an arbitrary solution to a problem, then attempts to find a better solution by incrementally changing a single element of the solution. If the change produces a better solution, an incremental change is made to the new solution, repeating until no further improvements can be found.
But in the context of the CoreCLR, ‘Hill Climbing’ (HC) is used to control the rate at which threads are added to the Thread Pool, from the MSDN page on ‘Parallel Tasks’:
Thread Injection
The .NET thread pool automatically manages the number of worker threads in the pool. It adds and removes threads according to built-in heuristics. The .NET thread pool has two main mechanisms for injecting threads: a starvation-avoidance mechanism that adds worker threads if it sees no progress being made on queued items and a hill-climbing heuristic that tries to maximize throughput while using as few threads as possible. … A goal of the hill-climbing heuristic is to improve the utilization of cores when threads are blocked by I/O or other wait conditions that stall the processor …. The .NET thread pool has an opportunity to inject threads every time a work item completes or at 500 millisecond intervals, whichever is shorter. The thread pool uses this opportunity to try adding threads (or taking them away), guided by feedback from previous changes in the thread count. If adding threads seems to be helping throughput, the thread pool adds more; otherwise, it reduces the number of worker threads. This technique is called the hill-climbing heuristic.
For more specifics on what the algorithm is doing, you can read the research paper Optimizing Concurrency Levels in the .NET ThreadPool published by Microsoft, although it you want a brief outline of what it’s trying to achieve, this summary from the paper is helpful:
In addition the controller should have:
- short settling times so that cumulative throughput is maximized
- minimal oscillations since changing control settings incurs overheads that reduce throughput
- fast adaptation to changes in workloads and resource characteristics.
So reduce throughput, don’t add and then remove threads too fast, but still adapt quickly to changing work-loads, simple really!!
As an aside, after reading (and re-reading) the research paper I found it interesting that a considerable amount of it was dedicated to testing, as the following excerpt shows:

In fact the approach to testing was considered so important that they wrote an entire follow-up paper that discusses it, see Configuring Resource Managers Using Model Fuzzing.
Why is it needed?
Because, in short, just adding new threads doesn’t always increase throughput and ultimately having lots of threads has a cost. As this comment from Eric Eilebrecht, one of the authors of the research paper explains:
Throttling thread creation is not only about the cost of creating a thread; it’s mainly about the cost of having a large number of running threads on an ongoing basis. For example:
- More threads means more context-switching, which adds CPU overhead. With a large number of threads, this can have a significant impact.
- More threads means more active stacks, which impacts data locality. The more stacks a CPU is having to juggle in its various caches, the less effective those caches are.
The advantage of more threads than logical processors is, of course, that we can keep the CPU busy if some of the threads are blocked, and so get more work done. But we need to be careful not to “overreact” to blocking, and end up hurting performance by having too many threads.
Or in other words, from Concurrency - Throttling Concurrency in the CLR 4.0 ThreadPool
As opposed to what may be intuitive, concurrency control is about throttling and reducing the number of work items that can be run in parallel in order to improve the worker ThreadPool throughput (that is, controlling the degree of concurrency is preventing work from running).
So the algorithm was designed with all these criteria in mind and was then tested over a large range of scenarios, to ensure it actually worked! This is why it’s often said that you should just leave the .NET ThreadPool alone, not try and tinker with it. It’s been heavily tested to work across a multiple situations and it was designed to adapt over time, so it should have you covered! (although of course, there are times when it doesn’t work perfectly!!)
The Algorithm in Action
As the source in now available, we can actually play with the algorithm and try it out in a few scenarios to see what it does. It needs very few dependences and therefore all the relevant code is contained in the following files:
(For comparison, there’s an implementation of the same algorithm in the Mono source code)
I have a project up on my GitHub page that allows you to test the hill-climbing algorithm in a self-contained console app. If you’re interested you can see the changes/hacks I had to do to get it building, although in the end it was pretty simple! (Update Kudos to Christian Klutz who ported my self-contained app to C#, nice job!!)
The algorithm is controlled via the following HillClimbing_XXX settings:
| Setting | Default Value | Notes |
|---|---|---|
| HillClimbing_WavePeriod | 4 | |
| HillClimbing_TargetSignalToNoiseRatio | 300 | |
| HillClimbing_ErrorSmoothingFactor | 1 | |
| HillClimbing_WaveMagnitudeMultiplier | 100 | |
| HillClimbing_MaxWaveMagnitude | 20 | |
| HillClimbing_WaveHistorySize | 8 | |
| HillClimbing_Bias | 15 | The ‘cost’ of a thread. 0 means drive for increased throughput regardless of thread count; higher values bias more against higher thread counts |
| HillClimbing_MaxChangePerSecond | 4 | |
| HillClimbing_MaxChangePerSample | 20 | |
| HillClimbing_MaxSampleErrorPercent | 15 | |
| HillClimbing_SampleIntervalLow | 10 | |
| HillClimbing_SampleIntervalHigh | 200 | |
| HillClimbing_GainExponent | 200 | The exponent to apply to the gain, times 100. 100 means to use linear gain, higher values will enhance large moves and damp small ones |
Because I was using the code in a self-contained console app, I just hard-coded the default values into the source, but in the CLR it appears that you can modify these values at runtime.
Working with the Hill Climbing code
There are several things I discovered when implementing a simple test app that works with the algorithm:
- The calculation is triggered by calling the function
HillClimbingInstance.Update(currentThreadCount, sampleDuration, numCompletions, &threadAdjustmentInterval)and the return value is the new ‘maximum thread count’ that the algorithm is proposing. - It calculates the desired number of threads based on the ‘current throughput’, which is the ‘# of tasks completed’ (
numCompletions) during the current time-period (sampleDurationin seconds). - It also takes the current thread count (
currentThreadCount) into consideration. - The core calculations (excluding error handling and house-keeping) are only just over 100 LOC, so it’s not too hard to follow.
- It works on the basis of ‘transitions’ (
HillClimbingStateTransition), firstWarmup, thenStabilizingand will only recommend a new value once it’s moved into theClimbingMovestate. - The real .NET Thread Pool only increases the thread-count by one thread every 500 milliseconds. It keeps doing this until the ‘# of threads’ has reached the amount that the hill-climbing algorithm suggests. See ThreadpoolMgr::ShouldAdjustMaxWorkersActive() and ThreadpoolMgr::AdjustMaxWorkersActive() for the code that handles this.
- If it hasn’t got enough samples to do a ‘statistically significant’ calculation this algorithm will indicate this via the
threadAdjustmentIntervalvariable. This means that you should not callHillClimbingInstance.Update(..)until anotherthreadAdjustmentIntervalmilliseconds have elapsed. (link to source code that calculates this) - The current thread count is only decreased when threads complete their current task. At that point the current count is compared to the desired amount and if necessary a thread is ‘retired’
- The algorithm with only returns values that respect the limits specified by ThreadPool.SetMinThreads(..) and ThreadPool.SetMaxThreads(..) (link to the code that handles this)
- In addition, it will only recommend increasing the thread count if the CPU Utilization is below 95%
First lets look at the graphs that were published in the research paper from Microsoft (Optimizing Concurrency Levels in the .NET ThreadPool):
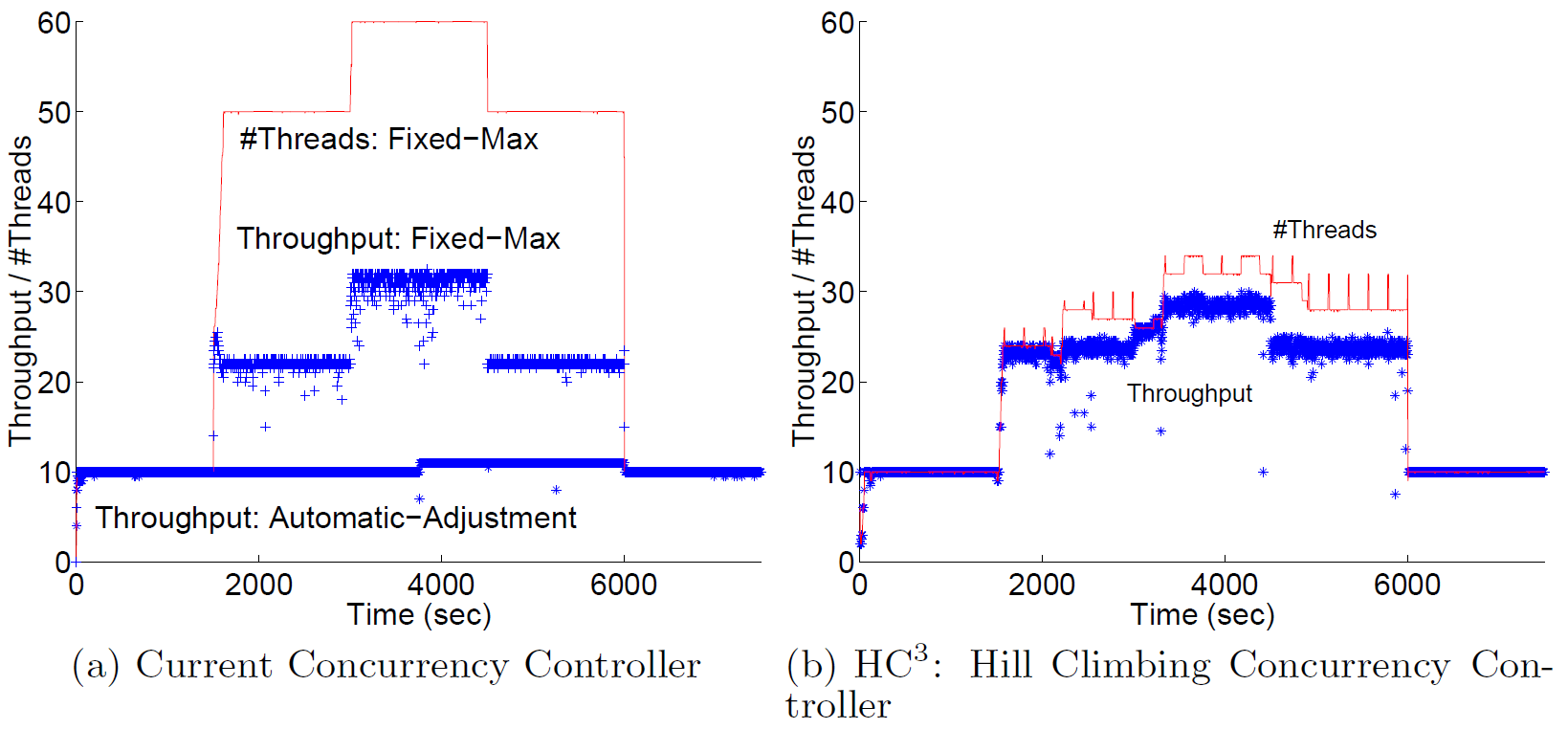
They clearly show the thread-pool adapting the number of threads (up and down) as the throughput changes, so it appears the algorithm is doing what it promises.
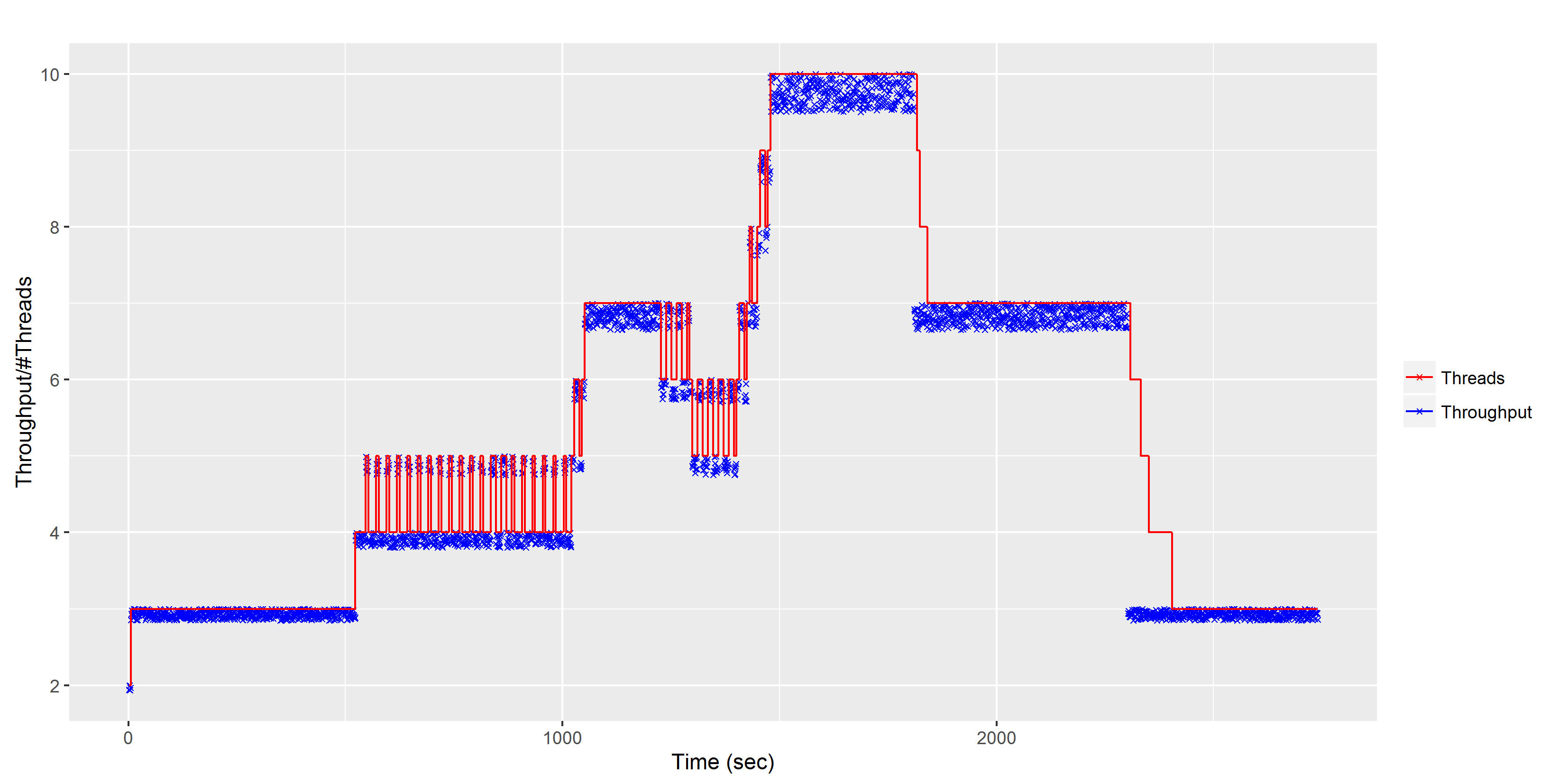
Now for a similar image using the self-contained test app I wrote. Now, my test app only pretends to add/remove threads based on the results for the Hill Climbing algorithm, so it’s only an approximation of the real behaviour, but it does provide a nice way to see it in action outside of the CLR.
In this simple scenario, the work-load that we are asking the thread-pool to do is just moving up and then down (click for full-size image):
Finally, we’ll look at what the algorithm does in a more noisy scenario, here the current ‘work load’ randomly jumps around, rather than smoothly changing:
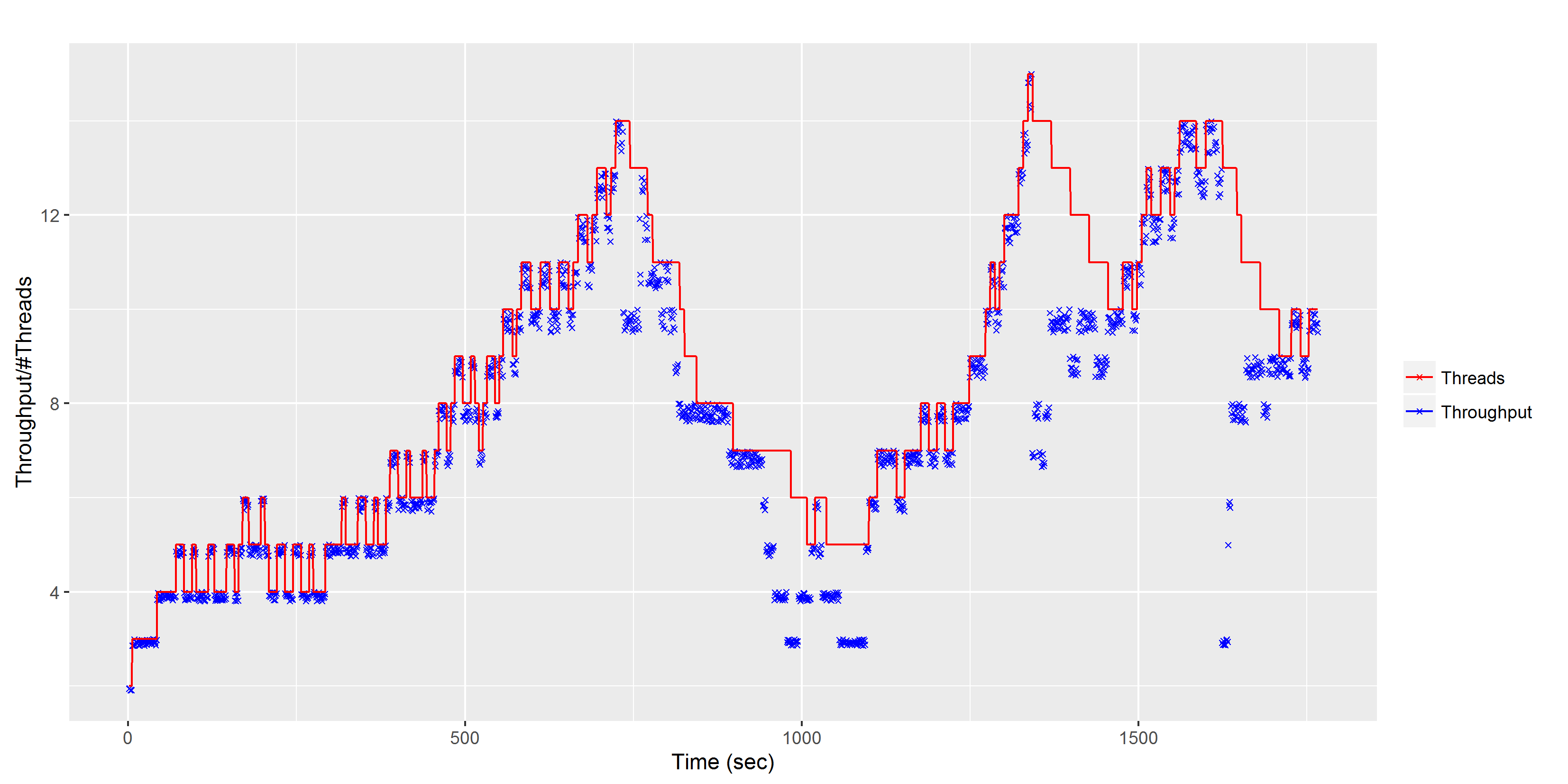
So with a combination of a very detailed MSDN article, a easy-to-read research paper and most significantly having the source code available, we are able to get an understanding of what the .NET Thread Pool is doing ‘under-the-hood’!
References
- Concurrency - Throttling Concurrency in the CLR 4.0 ThreadPool (I recommend reading this article before reading the research papers)
- Optimizing Concurrency Levels in the .NET ThreadPool: A case study of controller design and implementation
- direct link to PDF file
- Configuring Resource Managers Using Model Fuzzing: A Case Study of the .NET Thread Pool
- direct link to PDF file
- MSDN page on ‘Parallel Tasks’ (see section on ‘Thread Injection’)
- Patent US20100083272 - Managing pools of dynamic resources
Further Reading
- Erika Parsons and Eric Eilebrecht - CLR 4 - Inside the Thread Pool - Channel 9
- New and Improved CLR 4 Thread Pool Engine (Work-stealing and Local Queues)
- .NET CLR Thread Pool Internals (compares the new Hill Climbing algorithm, to the previous algorithm used in the Legacy Thread Pool)
- CLR thread pool injection, stuttering problems
- Why the CLR 2.0 SP1’s threadpool default max thread count was increased to 250/CPU
- Use a more dependable policy for thread pool thread injection (CoreCLR GitHub Issue)
- Use a more dependable policy for thread pool thread injection (CoreFX GitHub Issue)
- ThreadPool Growth: Some Important Details
- .NET’s ThreadPool Class - Behind The Scenes (Based on SSCLI source, not CoreCLR)
- CLR Execution Context (in Russian, but Google Translate does a reasonable job)
- Thread Pool + Task Testing (by Ben Adams)
- The Injector: A new Executor for Java (an improved thread-injector for the Java Thread Pool)
Discuss this post on Hacker News and /r/programming