Analysing Optimisations in the Wire Serialiser
23 Aug 2016 - 1310 wordsRecently Roger Johansson wrote a post titled Wire – Writing one of the fastest .NET serializers, describing the optimisation that were implemented to make Wire as fast as possible. He also followed up that post with a set of benchmarks, showing how Wire compared to other .NET serialisers:
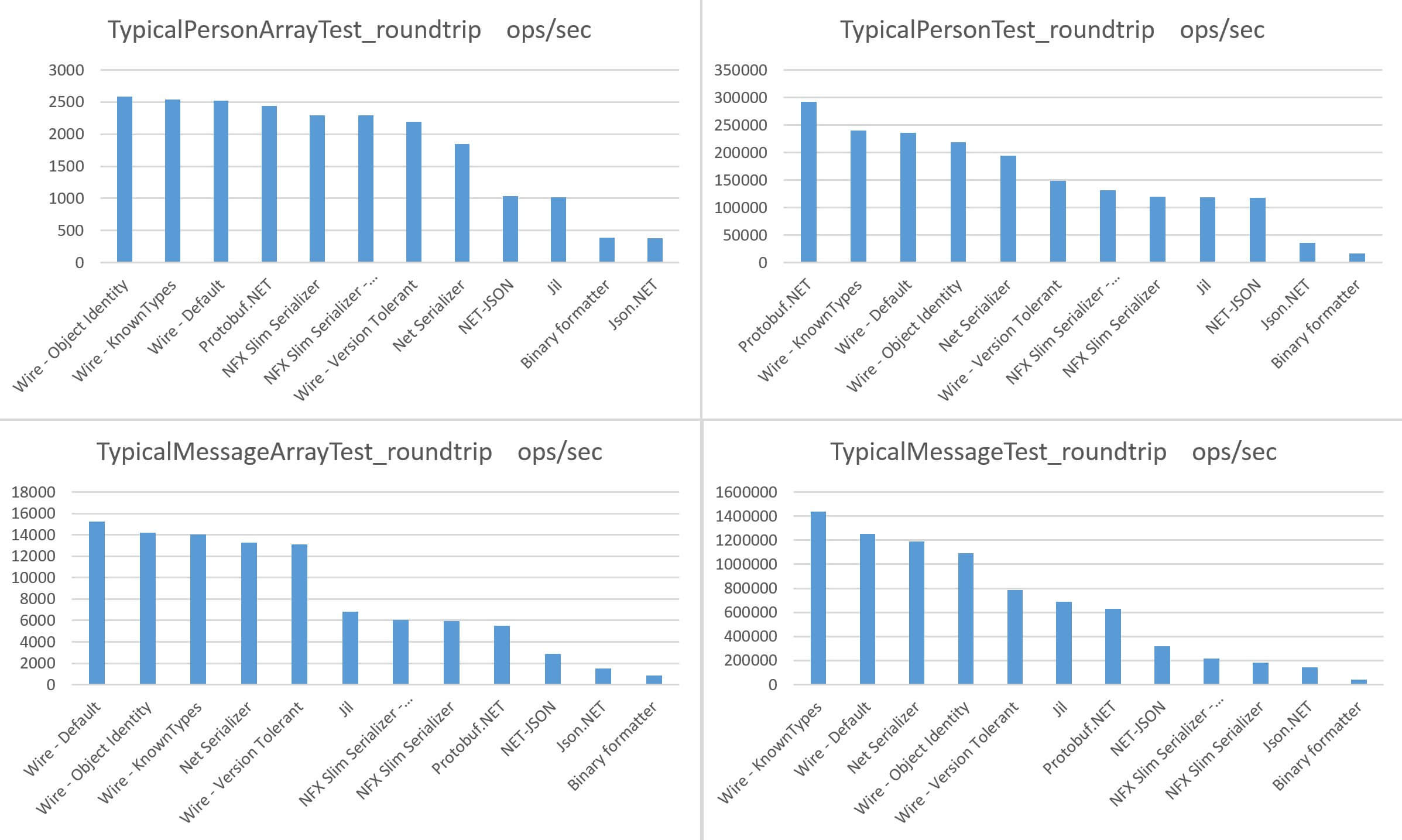
Using BenchmarkDotNet, this post will analyse the individual optimisations and show how much faster each change is. For reference, the full list of optimisations in the original blog post are:
- Looking up value serializers by type
- Looking up types when deserializing
- Byte buffers, allocations and GC
- Clever allocations
- Boxing, Unboxing and Virtual calls
- Fast creation of empty objects
Looking up value serializers by type
This optimisation changed code like this:
public ValueSerializer GetSerializerByType(Type type)
{
ValueSerializer serializer;
if (_serializers.TryGetValue(type, out serializer))
return serializer;
//more code to build custom type serializers.. ignore for now.
}
into this:
public ValueSerializer GetSerializerByType(Type type)
{
if (ReferenceEquals(type.GetTypeInfo().Assembly, ReflectionEx.CoreAssembly))
{
if (type == TypeEx.StringType) //we simply keep a reference to each primitive type
return StringSerializer.Instance;
if (type == TypeEx.Int32Type)
return Int32Serializer.Instance;
if (type == TypeEx.Int64Type)
return Int64Serializer.Instance;
...
}
So it has replaced a dictionary lookup with an if statement. In addition it is caching the Type instance of known types, rather than calculating them every time. As you can see the optimisation pays off in some circumstance but not in others, so it’s not a clear win. It depends on where the type is in the list of if statements. If it’s near the beginning (e.g. System.String) it’ll be quicker than if it’s near the end (e.g. System.Byte[]), which makes sense as all the other comparisons have to be done first.
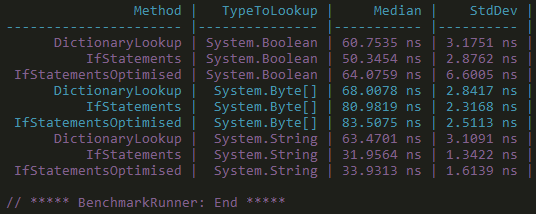
Full benchmark code and results
Looking up types when deserializing
The 2nd optimisation works by removing all unnecessary memory allocations, it did this by:
- Using a custom
struct(value type) rather than aclass - Pre-calculating a hash code once, rather than each time a comparison is needed.
- Doing string comparisons with raw
byte [], rather than deserialising to astring

Full benchmark code and results
Note: these results nicely demonstrate how BenchmarkDotNet can show you memory allocations as well as the time taken.
Interestingly they hadn’t actually removed all memory allocations as the comparisons between OptimisedLookup and OptimisedLookupCustomComparer show. To fix this I sent a P.R which removes unnecessary boxing, by using a Custom Comparer rather than the default struct comparer.
Byte buffers, allocations and GC
Again removing unnecessary memory allocations were key in this optimisation, most of which can be seen in the NoAllocBitConverter. Clearly serialisation spends a lot of time converting from the in-memory representation of an object to the serialised version, i.e. a byte []. So several tricks were employed to ensure that temporary memory allocations were either removed completely or if that wasn’t possible, they were done by re-using a buffer from a pool rather than allocating a new one each time (see “Buffer recycling”)

Full benchmark code and results
Clever allocations
This optimisation is perhaps the most interesting, because it’s implemented by creating a custom data structure, tailored to the specific needs of Wire. So, rather than using the default .NET dictionary, they implemented FastTypeUShortDictionary. In essence this data structure optimises for having only 1 item, but falls back to a regular dictionary when it grows larger. To see this in action, here is the code from the TryGetValue(..) method:
public bool TryGetValue(Type key, out ushort value)
{
switch (_length)
{
case 0:
value = 0;
return false;
case 1:
if (key == _firstType)
{
value = _firstValue;
return true;
}
value = 0;
return false;
default:
return _all.TryGetValue(key, out value);
}
}
Like we’ve seen before, the performance gains aren’t clear-cut. For instance it depends on whether FastTypeUShortDictionary contains the item you are looking for (Hit v Miss), but generally it is faster:
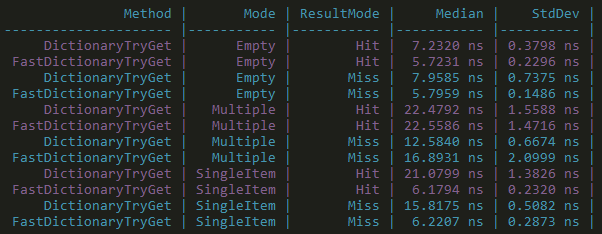
Full benchmark code and results
Boxing, Unboxing and Virtual calls
This optimisation is based on the widely used trick that I imagine almost all .NET serialisers employ. For a serialiser to be generic, is has to be able to handle any type of object that is passed to it. Therefore the first thing it does is use reflection to find the public fields/properties of that object, so that it knows the data is has to serialise. Doing reflection like this time-and-time again gets expensive, so the way to get round it is to do reflection once and then use dynamic code generation to compile a delegate than you can then call again and again.
If you are interested in how to implement this, see the Wire compiler source or this Stack Overflow question. As shown in the results below, compiling code dynamically is much faster than reflection and only a little bit slower than if you read/write the property directly in C# code:
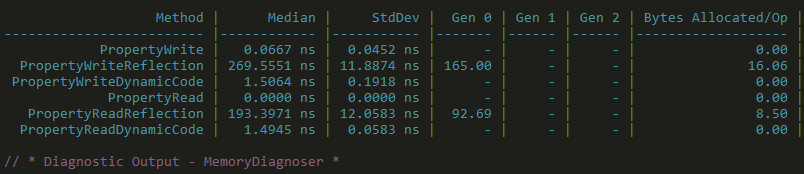
Full benchmark code and results
Fast creation of empty objects
The final optimisation trick used is also based on dynamic code creation, but this time it is purely dealing with creating empty objects. Again this is something that a serialiser does many time, so any optimisations or savings are worth it.
Basically the benchmark is comparing code like this:
FormatterServices.GetUninitializedObject(type);
with dynamically generated code, based on Expression trees:
var newExpression = ExpressionEx.GetNewExpression(typeToUse);
Func<TestClass> optimisation = Expression.Lambda<Func<TestClass>>(newExpression).Compile();
However this trick only works if the constructor of the type being created is empty, otherwise it has to fall back to the slow version. But as shown in the results below, we can see that the optimisation is a clear win and worth implementing:
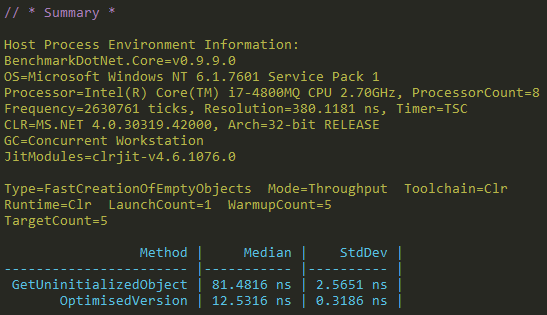
Full benchmark code and results
Summary
So it’s obvious that Roger Johansson and Szymon Kulec (who also contributed performance improvements) know their optimisations and as a result they have steadily made the Wire serialiser faster, which makes is an interesting project to learn from.