The Stack Overflow Tag Engine – Part 3
29 Oct 2015 - 1564 wordsThis is the part 3 of a mini-series looking at what it might take to build the Stack Overflow Tag Engine, if you haven’t read part 1 or part 2, I recommend reading them first.
Complex boolean queries
One of the most powerful features of the Stack Overflow Tag Engine is that it allows you to do complex boolean queries against multiple Tag, for instance:
A simple way of implementing this is to write code like below, which makes use of a HashSet to let us efficiently do lookups to see if a particular questions should be included or excluded.
var result = new List<Question>(pageSize);
var andHashSet = new HastSet<int>(queryInfo[tag2]);
foreach (var id in queryInfo[tag1])
{
if (result.Count >= pageSize)
break;
baseQueryCounter++;
if (questions[id].Tags.Any(t => tagsToExclude.Contains(t)))
{
excludedCounter++;
}
else if (andHashSet.Remove(item))
{
if (itemsSkipped >= skip)
result.Add(questions[item]);
else
itemsSkipped++;
}
}
The main problem is that we have to scan through all the ids for tag1 until we have enough matches, i.e. foreach (var id in queryInfo[tag1]). In addition we have to initially load up the HashSet with all the ids for tag2, so that we can check matches. So this method takes longer as we skip more and more questions, i.e. for larger value of skip or if there are a large amount of tagsToExclude (i.e. “Ignored Tags”), see Part 2 for more infomation.
Bitmaps
So can we do any better, well yes, there is a fairly established mechanism for doing these types of queries, known as Bitmap indexes. To use these you have to pre-calculate an index in which each bit is set to 1 to indicate a match and 0 otherwise. In our scenario this looks so:
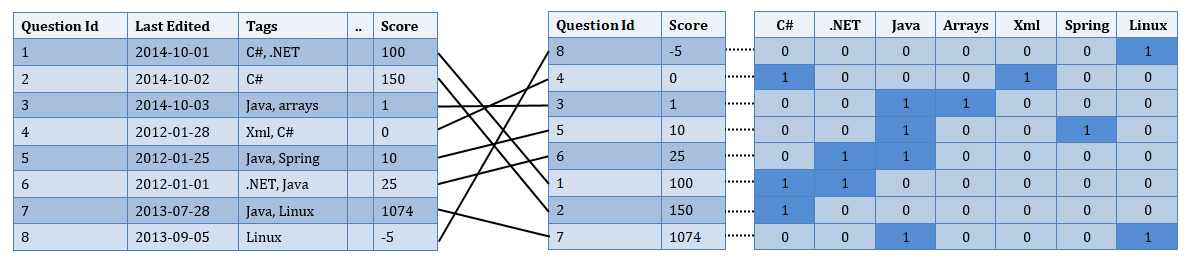
Then it is just a case of doing the relevant bitwise operations against the bits (a byte at a time), for example if you want to get the questions that have the C# AND Java Tags, you do the following:
for (int i = 0; i < numBits / 8; i++)
{
result[i] = bitSetCSharp[i] & bitSetJava[i];
}
The main drawback is that we have to create a Bitmap index for each tag (C#, .NET, Java, etc) for every sort order (LastActivityDate, CreationDate, Score, ViewCount, AnswerCount), so we soon use up a lot of memory. The Sept 2014 Stack Overflow dataset contains just under 8 million questions and so at 8 questions per byte, a single Bitmap needs 976KB or 0.95MB. This adds up to an impressive 149GB (0.95MB * 32,000 Tags * 5 sort orders).
Compressed Bitmaps
Fortunately there is a way to heavily compress the Bitmaps using a form of Run-length encoding, to do this I made use of the C# version of the excellent EWAH library. This library is based on the research carried out in the paper Sorting improves word-aligned bitmap indexes by Daniel Lemire and others. By using EWAH it has the added benefit that you don’t need to uncompress the Bitmap to perform the bitwise operations, they can be done in-place (for an idea of how this is done take a look at this commit where I added a single in-place AndNot function to the existing library).
However if you don’t want to read the research paper, the diagram below shows how the Bitmap is compressed into 64-bit words that have 1 or more bits set, plus runs of repeating zeros or ones. So 31 0x00 indicates that 31 instances of a 64-bit word (with all the bits set to 0) have be encoded as a single value, rather than as 31 individual words.
0 0x00
1 words
[ 0]= 17, 2 bits set ->
{0000000000000000000000000000000000000000000000000000000000010001}
31 0x00
1 words
[ 0]= 2199023255552, 1 bits set ->
{0000000000000000000000100000000000000000000000000000000000000000}
18 0x01
1 words
[ 0]= 64, 1 bits set ->
{0000000000000000000000000000000000000000000000000000000001000000}
48 0x01
3 words
[ 0]= 1048576, 1 bits set ->
{0000000000000000000000000000000000000000000100000000000000000000}
[ 1]= 9007199254740992, 1 bits set ->
{0000000000100000000000000000000000000000000000000000000000000000}
[ 2]= 9007199304740992, 13 bits set ->
{0000000000100000000000000000000000000010111110101111000010000000}
131 0x00
1 words
[ 0]= 536870912, 1 bits set ->
{0000000000000000000000000000000000100000000000000000000000000000}
....
To give an idea of the space savings that can be achieved, the table below shows the size in bytes for compressed Bitmaps that have varying amounts of individual bit set to 1 (for comparision uncompressed Bitmaps are 1,000,000 bytes or 0.95MB)
| # Bits Set | Size in Bytes |
|---|---|
| 1 | 24 |
| 10 | 168 |
| 25 | 408 |
| 50 | 808 |
| 100 | 1,608 |
| 200 | 3,208 |
| 400 | 6,408 |
| 800 | 12,808 |
| 1,600 | 25,608 |
| 32,000 | 512,008 |
| 64,000 | 1,000,008 |
| 128,000 | 1,000,008 |
As you can see it’s not until we get over 64,000 bits (62,016 to be precise) that we match the size of the regular Bitmaps. Note: in these tests I was setting the bits with an evenly spaced distribution across the entire range of 8 million possible bits. The compression is also dependant on which bits are set, so this is a worse case. The more the bits are clumped together (within the same byte), the more it will be compressed.
So over the entire Stack Overflow data set of 32,000 Tags, the Bitmaps compress down to an impressive 1.17GB, compared to 149GB uncompressed!
Results
But do queries against compressed Bitmaps actually perform faster than the naive queries using HashSets (see code above). Well yes they do and in some cases the difference is significant.
As you can see below, for AND NOT queries they are much faster, especially compared to the worse-case where the regular/naive code takes over 150 ms and the compressed Bitmap code takes ~5 ms (the x-axis is # of excluded/skipped questions and the y-axis is time in milliseconds).
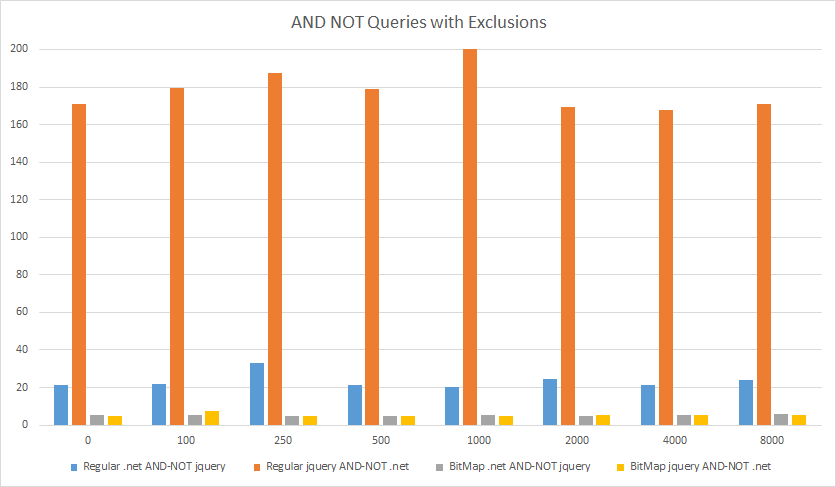
For reference there are 194,384 questions tagged with .net and 528,490 tagged with jquery.
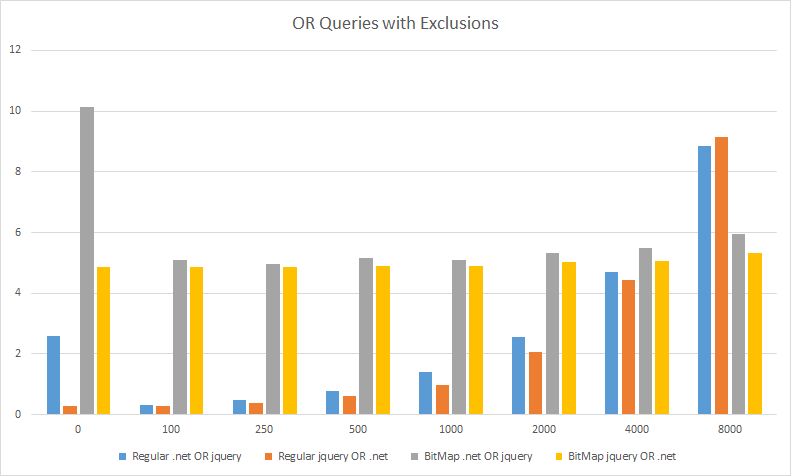
To ensure I’m being fair, I should point out that the compressed Bitmap queries are slower for OR queries, as shown below. But note the scale, they take ~5 ms compared to ~1-2 ms for the regular queries, so the compressed Bitmap queries are still fast! The nice things about the compressed Bitmap queries is that they take the same amount of time, regardless of how many questions we skip, whereas the regular queries get slower as # of excluded/skipped questions increases.
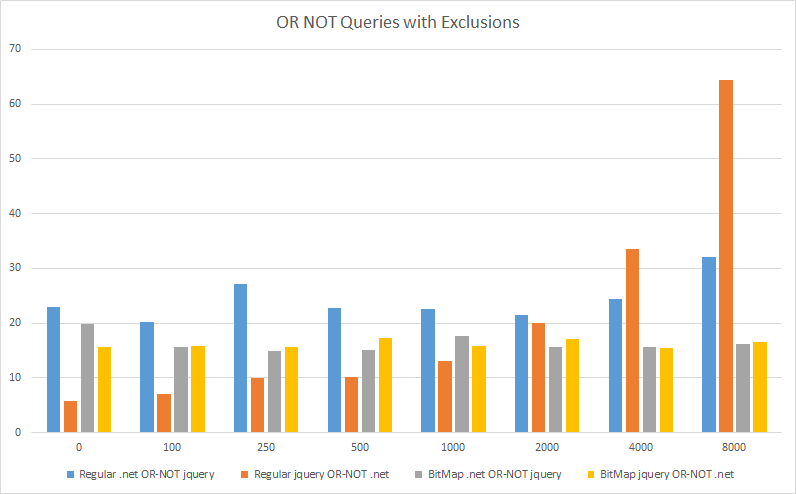
If you are interested the results for all the query types are available:
{kind=link}
{kind=link}
Further Reading
- Bitmaps
- The mythical bitmap index
- Roaring Bitmaps (a newer/faster compressed Bit Map implementation)
- When is a bitmap faster than an integer list
- Using bitmap indexes in databases
- Interesting Hacker News discussion on Roaring Bitmaps
- Research into different Bitmap implementations
- Real-world usage
Future Posts
But there’s still more things to implement, in future posts I hope to cover the following:
- Currently my implementation doesn’t play nicely with the Garbage Collector and it does lots of allocations. I will attempt to replicate the “no-allocations” rule that Stack Overflow have after their battle with the .NET GC
- How a DDOS attack on TagServer might have been caused
In October, we had a situation where a flood of crafted requests were causing high resource utilization on our Tag Engine servers, which is our internal application for associating questions and tags in a high-performance way.