Fuzzing the .NET JIT Compiler
28 Aug 2018 - 2941 wordsI recently came across the excellent ‘Fuzzlyn’ project, created as part of the ‘Language-Based Security’ course at Aarhus University. As per the project description Fuzzlyn is a:
… fuzzer which utilizes Roslyn to generate random C# programs
And what is a ‘fuzzer’, from the Wikipedia page for ‘fuzzing’:
Fuzzing or fuzz testing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program.
Or in other words, a fuzzer is a program that tries to create source code that finds bugs in a compiler.
Massive kudos to the developers behind Fuzzlyn, Jakob Botsch Nielsen (who helped answer my questions when writing this post), Chris Schmidt and Jonas Larsen, it’s an impressive project!! (to be clear, I have no link with the project and can’t take any of the credit for it)
Compilation in .NET
But before we dive into ‘Fuzzlyn’ and what it does, we’re going to take a quick look at ‘compilation’ in the .NET Framework. When you write C#/VB.NET/F# code (delete as appropriate) and compile it, the compiler converts it into Intermediate Language (IL) code. The IL is then stored in a .exe or .dll, which the Common Language Runtime (CLR) reads and executes when your program is actually run. However it’s the job of the Just-in-Time (JIT) Compiler to convert the IL code into machine code.
Why is this relevant? Because Fuzzlyn works by comparing the output of a Debug and a Release version of a program and if they are different, there’s a bug! But it turns out that very few optimisations are actually done by the ‘Roslyn’ compiler, compared to what the JIT does, from Eric Lippert’s excellent post What does the optimize switch do? (2009)
The /optimize flag does not change a huge amount of our emitting and generation logic. We try to always generate straightforward, verifiable code and then rely upon the jitter to do the heavy lifting of optimizations when it generates the real machine code. But we will do some simple optimizations with that flag set. For example, with the flag set:
He then goes on to list the 15 things that the C# Compiler will optimise, before finishing with this:
That’s pretty much it. These are very straightforward optimizations; there’s no inlining of IL, no loop unrolling, no interprocedural analysis whatsoever. We let the jitter team worry about optimizing the heck out of the code when it is actually spit into machine code; that’s the place where you can get real wins.
So in .NET, very few of the techniques that an ‘Optimising Compiler’ uses are done at compile-time. They are almost all done at run-time by the JIT Compiler (leaving aside AOT scenarios for the time being).
For reference, most of the differences in IL are there to make the code easier to debug, for instance given this C# code:
public void M() {
foreach (var item in new [] { 1, 2, 3, 4 }) {
Console.WriteLine(item);
}
}
The differences in IL are shown below (‘Release’ on the left, ‘Debug’ on the right). As you can see there are a few extra nop instructions to allow the debugger to ‘step-through’ more locations in the code, plus an extra local variable, which makes it easier/possible to see the value when debugging.
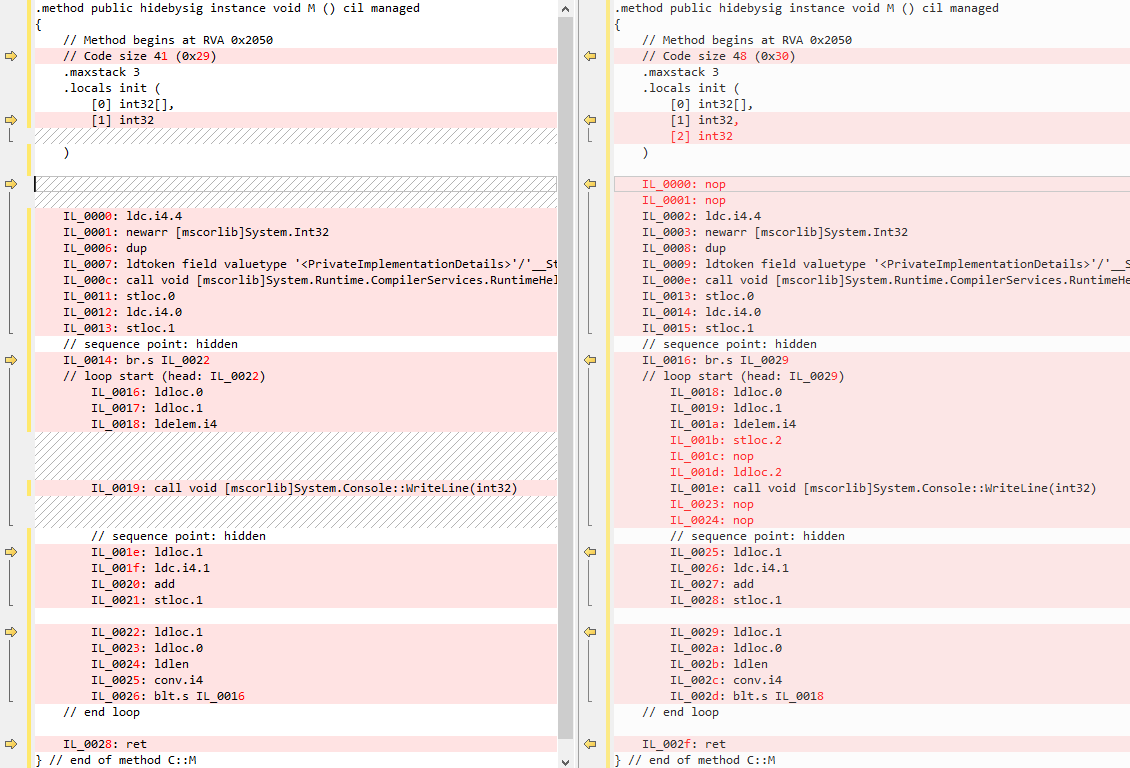
(click for larger image or you can view the ‘Release’ version and the ‘Debug’ version on the excellent SharpLab)
For more information on the differences in Release/Debug code-gen see the ‘Release (optimized)’ section in this doc on CodeGen Differences. Also, because Roslyn is open-source we can see how this is handled in the code:
- All usages of the ‘OptimizationLevel’ enum
- All usage of the ‘ILEmitStyle’ enum
- In Debug builds, extra ‘sequence points’ are created (as shown above)
- Extra field added to the the async/await ‘State Machine’ in Debug builds
- In Release builds, some ‘catch’ blocks are discarded
- In Debug builds, hoisted variables aren’t re-used
- Extra Attribute is inserted in Debug builds
This all means that the ‘Fuzzlyn’ project has actually been finding bugs in the .NET JIT, not in the Roslyn Compiler
(well, except this one Finally block belonging to unexecuted try runs anyway, which was fixed here)
How it works
At the simplest level, Fuzzlyn works by compiling and running a piece of randomly generated code in ‘Debug’ and ‘Release’ versions and comparing the output. If the 2 versions produce different results, then it’s a bug, specifically a bug in the optimisations that the JIT compiler has attempted.
The .NET JIT, known as ‘RyuJIT’, has several modes. It can produce fully optimised code that has the highest-performance, or in can produce more ‘debug’ friendly code that has no optimisations, but is much simpler. You can find out more about the different ‘optimisations’ that RyuJIT performs in this excellent tutorial, in this design doc or you can search through the code for usages of the ‘compDbgCode’ flag.
From a high-level Fuzzlyn goes through the following steps:
- Randomly generate a C# program
- Check if the code produces an error (Debug v. Release)
- Reduce the code to it’s simplest form
If you want to see this in action, I ran Fuzzlyn until it produced a randomly generated program with a bug. You can see the original source (6,802 LOC) and the reduced version (28 LOC). What’s interesting is that you can clearly see the buggy line-of-code in the original code, before it’s turned into a simplified version:
// Generated by Fuzzlyn v1.1 on 2018-08-22 15:19:26
// Seed: 14928117313359926641
// Reduced from 256.3 KiB to 0.4 KiB in 00:01:58
// Debug: Prints 0 line(s)
// Release: Prints 1 line(s)
public class Program
{
static short s_18;
static byte s_33 = 1;
static int[] s_40 = new int[]{0};
static short s_74 = 1;
public static void Main()
{
s_18 = -1;
// This comparision is the bug, in Debug it's False, in Release it's True
// However, '(ushort)(s_18 | 2L)' is 65,535 in Debug *and* Release
if (((ushort)(s_18 | 2L) <= s_40[0]))
{
s_74 = 0;
}
bool vr10 = s_74 < s_33;
if (vr10)
{
System.Console.WriteLine(0);
}
}
}
Random Code Generation
Fuzzlyn can’t produce every type of C# program, however it does support quite a few language features, from Supported constructs:
Fuzzlyn generates only a limited subset of C#. Most importantly, it does not support loops yet. It supports structs and classes, though it does not generate member methods in these. We make no attempt to fully support all kinds of expressions and statements.
To see the code for these generators, follow the links below:
- CodeGenerator
- LiteralGenerator
- FuncGenerator, with specific generator for a:
- Binary Operation tables, which are themselves generated using Roslyn
All the statements and expressions that are currently supported are listed here. Interestingly enough the type of statement/expression chosen is not completely random, instead that are chosen using probability tables, that look like this:
public ProbabilityDistribution StatementTypeDist { get; set; }
= new TableDistribution(new Dictionary<int, double>
{
[(int)StatementKind.Assignment] = 0.57,
[(int)StatementKind.If] = 0.17,
[(int)StatementKind.Block] = 0.1,
[(int)StatementKind.Call] = 0.1,
[(int)StatementKind.TryFinally] = 0.05,
[(int)StatementKind.Return] = 0.01,
});
As we saw before, the initial program that Fuzzlyn produces is quite large (over 5,000 LOC), so why does it create and execute a very large program?
Partly because it’s quicker to do this compared to working with lots of smaller programs, i.e. the steps of generation, compilation and starting new processes can be reduced by running large programs.
In addition, Jakob explained the other reasons:
- Empirically, other similar projects have shown that larger programs are better. Csmith authors report that most bugs were found with examples of around 80 KB (I don’t remember the exact number). We actually found the same thing in v1.0 – our examples had an average size of 76 KB
- Small programs do not get as many opportunities to generate a lot of patterns. For example, it is very unlikely that a small program will have a method taking a
byteparameter and at the same time, a method returning aref byte(this pattern has a bug on Linux: dotnet/coreclr#19256).- We mainly adjusted our probabilities based on how the examples looked. We strived for the generator to produce code that looked relatively like human code. This included going for a wide range of program sizes. By the way, you can run Fuzzlyn with
--stats --num-programs=10000to get a view of the distribution of program sizes – it will output stats for every 500 programs generated.
‘Checking’ for bugs
To check if the behaviour of 2 samples diverge (in ‘Release’ v ‘Debug’ mode), the tool inserts checksum-related code throughout the program. For example here’s a randomly generated method, note the calls to the Checksum(..) function at the end:
static sbyte M15(int arg0)
{
bool var0 = -71 < s_1;
uint var1 = (uint)(1UL & s_4++);
if (var0)
{
var0 = var0;
arg0 = arg0;
}
else
{
ref ushort var2 = ref s_4;
var2 = var2;
s_rt.Checksum("c_17", var2);
}
uint var3 = var1;
short[] var4 = s_2[0][0];
s_rt.Checksum("c_18", arg0);
s_rt.Checksum("c_19", var0);
s_rt.Checksum("c_20", var1);
s_rt.Checksum("c_21", var3);
s_rt.Checksum("c_22", var4[0]);
return 0;
}
The checksums calls allow the execution of a program to be compared between ‘Release’ and ‘Debug’ modes, if a single variable has a different value, at any point during execution, the checksums will be different.
It’s also worth pointing out that Roslyn provides in-memory compilation that helps speed up this process because you don’t have to shell-out to an external process. As Jakob explains:
Additionally since we don’t have to start processes for every invocation when we use Roslyn’s in-memory compilation, we can compile and check for interesting behavior super fast. This allows our reducer to be really simple and dumb, while still giving great results.
‘Reducing’ the output
However, the checksums also help Fuzzlyn ‘Reduce’ the program from the large initial version to something much more readable. By using a ‘binary search’ technique it can remove a section of code and compare the checksums of the remaining code. If the checksums still differ then the remaining code contains the error/bug and Fuzzlyn can carry on reducing it, otherwise it can be discarded.
In addition, Fuzzlyn makes good use of the Roslyn ‘syntax tree’ API when removing code. For instance the CoarseStatementRemover class makes use of the Roslyn CSharpSyntaxWriter class, which is designed to allow syntax re-writing (also see Using a CSharp Syntax Rewriter).
The Results
What initially drew me to the Fuzzlyn project (aside from the great name) was the impressive results I saw it getting. As of the end of Aug 2018, they’re reported 22 bugs, of which 11 have already been fixed (kudos to the .NET JIT devs for fixing them so quickly).
Here’s a list of some of them, taken from the project README:
- NullReferenceException thrown for multi-dimensional arrays in release (fixed)
- Wrong integer promotion in release (fixed)
- Cast to ushort is dropped in release (fixed)
- Wrong value passed to generic interface method in release
- Constant-folding int.MinValue % -1
- Deterministic program outputs indeterministic results on Linux in release (fixed)
- RyuJIT incorrectly reorders expression containing a CSE, resulting in exception thrown in release
- RyuJIT incorrectly narrows value on ARM32/x86 in release (fixed)
- Invalid value numbering when morphing casts that changes signedness after global morph (fixed)
- RyuJIT spills 16 bit value but reloads as 32 bits in ARM32/x86 in release
- RyuJIT fails to preserve variable allocated to RCX around shift on x64 in release (fixed)
- RyuJIT: Invalid ordering when assigning ref-return (fixed)
- RyuJIT: Argument written to stack too early on Linux
- RyuJIT: Morph forgets about side effects when optimizing casted shift
- RyuJIT: By-ref assignment with null leads to runtime crash (fixed)
- RyuJIT: Mishandling of subrange assertion for rewritten call parameter
- RyuJIT: Incorrect ordering around Interlocked.Exchange and Interlocked.CompareExchange
(for the most up-to-date list see the GitHub Issues created by @jakobbotsch)
Summary
I think that Fuzzlyn is a fantastic project, anything that roots out bugs or undesired behaviour in the JIT is a great benefit to all .NET Developers. If you want a see what the potential side-effects of JIT bugs can be, take a look at Why you should wait on upgrading to .Net 4.6 by Nick Craver (one of the developers at Stack Overflow).
Now, you could argue that some of the code patterns that Fuzzlyn detects are not ones you’d normally write, e.g. if (((ushort)(s_18 | 2L) <= s_40[0])). But the wider point is that it’s valid C# code, which isn’t behaving as it should. Also, if you ever wrote this code you’d have a horrible time tracking down the problem because:
- Everyone knows that The First Rule of Programming: It’s Always Your Fault or “select” Isn’t Broken, i.e. getting to the point where you’re sure it is the compilers fault could take a while!
- If you tried to debug it, the problem would go away (Fuzzlyn only finds Debug v. Release differences). At which point you might begin to doubt your sanity!
Discuss this post on Hacker News, /r/dotnet or /r/csharp
Further Reading
Jakob was kind enough to share some additional links with me:
- Finding and Understanding Bugs in C Compilers (Csmith) (pdf)
- Test-Case Reduction for C Compiler Bugs (C-reduce) (pdf)
- QuickCheck: a lightweight tool for random testing of Haskell programs (pdf)
- This deals with test-case generation for general programs, not for compilers, but still an interesting paper nonetheless. QuickCheck also includes test case reduction, but unfortunately not much about it in their papers.
Also I asked him “Is any part of Fuzzlyn based on well known techniques, is it all implemented from scratch, or somewhere in-between?”
The state-of-the-art fuzzing techniques are unfortunately not well suited for testing the later stages of compilers (eg. the code output, optimization stages and so on). These techniques are for example symbolic execution, taint tracking, input length exploration, path slicing and more. The problem is that compilers use many intermediate representations, and it is hard to cross reference between what the fuzzer is passing in and what code is being executed at each stage. Even getting something to parse is hard without some kind of knowledge about what the structure needs to be. Fuzzlyn does not these techniques.
On the other hand, Fuzzlyn was very inspired by Csmith, which is a similar tool. But most of the code was written from scratch, since there is a big difference in generating C code (Csmith) and C# code. It is much more complicated to generate interesting C code that is free from undefined behavior.