Research papers in the .NET source
12 Dec 2016 - 2429 wordsThis post is completely inspired by (or ‘copied from’ depending on your point of view) a recent post titled JAVA PAPERS (also see the HackerNews discussion). However, instead of looking at Java and the JVM, I’ll be looking at references to research papers in the .NET language, runtime and compiler source code.
If I’ve missed any that you know of, please leave a comment below!
Note: I’ve deliberately left out links to specifications, standards documents or RFC’s, instead concentrating only on Research Papers.
‘Left Leaning Red Black trees’ by Robert Sedgewick - CoreCLR source reference
Abstract The red-black tree model for implementing balanced search trees, introduced by Guibas and Sedgewick thirty years ago, is now found throughout our computational infrastructure. Red-black trees are described in standard textbooks and are the underlying data structure for symbol-table implementations within C++, Java, Python, BSD Unix, and many other modern systems. However, many of these implementations have sacrificed some of the original design goals (primarily in order to develop an effective implementation of the delete operation, which was incompletely specified in the original paper), so a new look is worthwhile. In this paper, we describe a new variant of redblack trees that meets many of the original design goals and leads to substantially simpler code for insert/delete, less than one-fourth as much code as in implementations in common use.
‘Hopscotch Hashing’ by Maurice Herlihy, Nir Shavit, and Moran Tzafrir - CoreCLR source reference
Abstract We present a new class of resizable sequential and concur-rent hash map algorithms directed at both uni-processor and multicore machines. The new hopscotch algorithms are based on a novel hopscotch multi-phased probing and displacement technique that has the flavors of chaining, cuckoo hashing, and linear probing, all put together, yet avoids the limitations and overheads of these former approaches. The resulting algorithms provide tables with very low synchronization overheads and high cache hit ratios. In a series of benchmarks on a state-of-the-art 64-way Niagara II multi- core machine, a concurrent version of hopscotch proves to be highly scal-able, delivering in some cases 2 or even 3 times the throughput of today’s most efficient concurrent hash algorithm, Lea’s ConcurrentHashMap from java.concurr.util. Moreover, in tests on both Intel and Sun uni-processor machines, a sequential version of hopscotch consistently outperforms the most effective sequential hash table algorithms including cuckoo hashing and bounded linear probing. The most interesting feature of the new class of hopscotch algorithms is that they continue to deliver good performance when the hash table is more than 90% full, increasing their advantage over other algorithms as the table density grows.
‘Automatic Construction of Inlining Heuristics using Machine Learning’ by Kulkarni, Cavazos, Wimmer, and Simon. - CoreCLR source reference
Abstract Method inlining is considered to be one of the most important optimizations in a compiler. However, a poor inlining heuristic can lead to significant degradation of a program’s running time. Therefore, it is important that an inliner has an effective heuristic that controls whether a method is inlined or not. An important component of any inlining heuristic are the features that characterize the inlining decision. These features often correspond to the caller method and the callee methods. However, it is not always apparent what the most important features are for this problem or the relative importance of these features. Compiler writers developing inlining heuristics may exclude critical information that can be obtained during each inlining decision. In this paper, we use a machine learning technique, namely neuro-evolution [18], to automatically induce effective inlining heuristics from a set of features deemed to be useful for inlining. Our learning technique is able to induce novel heuristics that significantly out-perform manually-constructed inlining heuristics. We evaluate the heuristic constructed by our neuro-evolutionary technique within the highly tuned Java HotSpot server compiler and the Maxine VM C1X compiler, and we are able to obtain speedups of up to 89% and 114%, respectively. In addition, we obtain an average speedup of almost 9% and 11% for the Java HotSpot VM and Maxine VM, respectively. However, the output of neuro-evolution, a neural network, is not human readable. We show how to construct more concise and read-able heuristics in the form of decision trees that perform as well as our neuro-evolutionary approach.
‘A Theory of Objects’ by Luca Cardelli & Martín Abadi - CoreCLR source reference
Abstract Procedural languages are generally well understood. Their foundations have been cast in calculi that prove useful in matters of implementation and semantics. So far, an analogous understanding has not emerged for object-oriented languages. In this book the authors take a novel approach to the understanding of object-oriented languages by introducing object calculi and developing a theory of objects around them. The book covers both the semantics of objects and their typing rules, and explains a range of object-oriented concepts, such as self, dynamic dispatch, classes, inheritance, prototyping, subtyping, covariance and contravariance, and method specialization. Researchers and graduate students will find this an important development of the underpinnings of object-oriented programming.
‘Optimized Interval Splitting in a Linear Scan Register Allocator’ by Wimmer, C. and Mössenböck, D. - CoreCLR source reference
Abstract We present an optimized implementation of the linear scan register allocation algorithm for Sun Microsystems’ Java HotSpot™ client compiler. Linear scan register allocation is especially suitable for just-in-time compilers because it is faster than the common graph-coloring approach and yields results of nearly the same quality.Our allocator improves the basic linear scan algorithm by adding more advanced optimizations: It makes use of lifetime holes, splits intervals if the register pressure is too high, and models register constraints of the target architecture with fixed intervals. Three additional optimizations move split positions out of loops, remove register-to-register moves and eliminate unnecessary spill stores. Interval splitting is based on use positions, which also capture the kind of use and whether an operand is needed in a register or not. This avoids the reservation of a scratch register.Benchmark results prove the efficiency of the linear scan algorithm: While the compilation speed is equal to the old local register allocator that is part of the Sun JDK 5.0, integer benchmarks execute about 15% faster. Floating-point benchmarks show the high impact of the Intel SSE2 extensions on the speed of numeric Java applications: With the new SSE2 support enabled, SPECjvm98 executes 25% faster compared with the current Sun JDK 5.0.
‘Extensible pattern matching via a lightweight language extension’ by Don Syme, Gregory Neverov, James Margetson - Roslyn source reference
Abstract Pattern matching of algebraic data types (ADTs) is a standard feature in typed functional programming languages, but it is well known that it interacts poorly with abstraction. While several partial solutions to this problem have been proposed, few have been implemented or used. This paper describes an extension to the .NET language F# called active patterns, which supports pattern matching over abstract representations of generic heterogeneous data such as XML and term structures, including where these are represented via object models in other .NET languages. Our design is the first to incorporate both ad hoc pattern matching functions for partial decompositions and “views” for total decompositions, and yet remains a simple and lightweight extension. We give a description of the language extension along with numerous motivating examples. Finally we describe how this feature would interact with other reasonable and related language extensions: existential types quantified at data discrimination tags, GADTs, and monadic generalizations of pattern matching.
‘Some approaches to best-match file searching’ by W. A. Burkhard & R. M. Keller - Roslyn source reference
Abstract The problem of searching the set of keys in a file to find a key which is closest to a given query key is discussed. After “closest,” in terms of a metric on the the key space, is suitably defined, three file structures are presented together with their corresponding search algorithms, which are intended to reduce the number of comparisons required to achieve the desired result. These methods are derived using certain inequalities satisfied by metrics and by graph-theoretic concepts. Some empirical results are presented which compare the efficiency of the methods.
For reference, the links below take you straight the the GitHub searches, so you can take a look yourself:
Research produced by work on the .NET Runtime or Compiler
But what about the other way round, are there instances of work being done in .NET that is then turned into a research paper? Well it turns out there is, the first example I came across was from a tweet by Joe Duffy:
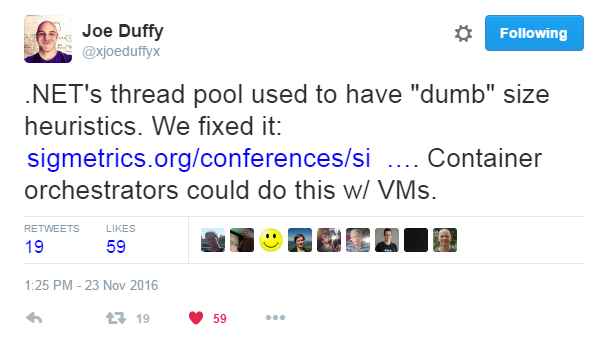
(As an aside, I recommend checking out Joe Duffy’s blog, it contains lots of information about Midori the research project to build a managed OS!)
‘Applying Control Theory in the Real World - Experience With Building a Controller for the .NET Thread Pool’ by Joseph L. Hellerstein, Vance Morrison, Eric Eilebrecht
Abstract There has been considerable interest in using control theory to build web servers, database managers, and other systems. We claim that the potential value of using control theory cannot be realized in practice without a methodology that addresses controller design, testing, and tuning. Based on our experience with building a controller for the .NET thread pool, we develop a methodology that: (a) designs for extensibility to integrate diverse control techniques, (b) scales the test infrastructure to enable running a large number of test cases, (c) constructs test cases for which the ideal controller performance is known a priori so that the outcomes of test cases can be readily assessed, and (d) tunes controller parameters to achieve good results for multiple performance metrics. We conclude by discussing how our methodology can be extended, especially to designing controllers for distributed systems.
‘Uniqueness and Reference Immutability for Safe Parallelism’ by Colin S. Gordon, Matthew Parkinson, Jared Parsons. Aleks Bromfield & Joe Duffy (alternative link)
Abstract A key challenge for concurrent programming is that side-effects (memory operations) in one thread can affect the behavior of another thread. In this paper, we present a type system to restrict the updates to memory to prevent these unintended side-effects. We provide a novel combination of immutable and unique (isolated) types that ensures safe parallelism (race freedom and deterministic execution). The type system includes support for polymorphism over type qualifiers, and can easily create cycles of immutable objects. Key to the system’s flexibility is the ability to recover immutable or externally unique references after violating uniqueness without any explicit alias tracking. Our type system models a prototype extension to C# that is in active use by a Microsoft team. We describe their experiences building large systems with this extension. We prove the soundness of the type system by an embedding into a program logic.
‘Design and Implementation of Generics for the .NET Common Language Runtime’ by Andrew Kennedy, Don Syme
Abstract The Microsoft .NET Common Language Runtime provides a shared type system, intermediate language and dynamic execution environment for the implementation and inter-operation of multiple source languages. In this paper we extend it with direct support for parametric polymorphism (also known as generics), describing the design through examples written in an extended version of the C# programming language, and explaining aspects of implementation by reference to a prototype extension to the runtime. Our design is very expressive, supporting parameterized types, polymorphic static, instance and virtual methods, “F-bounded” type parameters, instantiation at pointer and value types, polymorphic recursion, and exact run-time types. The implementation takes advantage of the dynamic nature of the runtime, performing justin-time type specialization, representation-based code sharing and novel techniques for efficient creation and use of run-time types. Early performance results are encouraging and suggest that programmers will not need to pay an overhead for using generics, achieving performance almost matching hand-specialized code.
‘Securing the .NET Programming Model (Industrial Application)’ by Andrew Kennedy
Abstract The security of the .NET programming model is studied from the standpoint of fully abstract compilation of C#. A number of failures of full abstraction are identified, and fixes described. The most serious problems have recently been fixed for version 2.0 of the .NET Common Language Runtime.
‘A Study of Concurrent Real-Time Garbage Collectors’ by Filip Pizlo, Erez Petrank & Bjarne Steensgaard (this features work done as part of Midori)
Abstract Concurrent garbage collection is highly attractive for real-time systems, because offloading the collection effort from the executing threads allows faster response, allowing for extremely short deadlines at the microseconds level. Concurrent collectors also offer much better scalability over incremental collectors. The main problem with concurrent real-time collectors is their complexity. The first concurrent real-time garbage collector that can support fine synchronization, STOPLESS, has recently been presented by Pizlo et al. In this paper, we propose two additional (and different) algorithms for concurrent real-time garbage collection: CLOVER and CHICKEN. Both collectors obtain reduced complexity over the first collector STOPLESS, but need to trade a benefit for it. We study the algorithmic strengths and weaknesses of CLOVER and CHICKEN and compare them to STOPLESS. Finally, we have implemented all three collectors on the Bartok compiler and runtime for C# and we present measurements to compare their efficiency and responsiveness.
‘STOPLESS: A Real-Time Garbage Collector for Multiprocessors’ by Filip Pizlo, Daniel Frampton, Erez Petrank, Bjarne Steensgaard
Abstract We present STOPLESS: a concurrent real-time garbage collector suitable for modern multiprocessors running parallel multithreaded applications. Creating a garbage-collected environment that supports real-time on modern platforms is notoriously hard, especially if real-time implies lock-freedom. Known real-time collectors either restrict the real-time guarantees to uniprocessors only, rely on special hardware, or just give up supporting atomic operations (which are crucial for lock-free software). STOPLESS is the first collector that provides real-time responsiveness while preserving lock-freedom, supporting atomic operations, controlling fragmentation by compaction, and supporting modern parallel platforms. STOPLESS is adequate for modern languages such as C# or Java. It was implemented on top of the Bartok compiler and runtime for C# and measurements demonstrate high responsiveness (a factor of a 100 better than previously published systems), virtually no pause times, good mutator utilization, and acceptable overheads.
Finally, a full list of MS Research publications related to ‘programming languages and software engineering’ is available if you want to explore more of this research yourself.
Discuss this post on Hacker News