Compact strings in the CLR
19 Sep 2016 - 1286 wordsIn the CLR strings are stored as a sequence of UTF-16 code units, i.e. an array of char items. So if we have the string ‘testing’, in memory it looks like this:
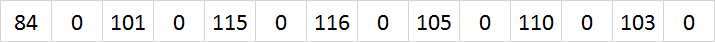
But look at all those zero’s, wouldn’t it be more efficient if it could be stored like this instead?
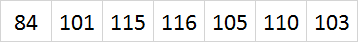
Now this is a contrived example, clearly not all strings are simple ASCII text that can be compacted this way. Also, even though I’m an English speaker, I’m well aware that there are other languages with character sets than can only be expressed in Unicode. However it turns out that even in a fully internationalised modern web-application, there are still a large amount of strings that could be expressed as ASCII, such as:
- Urls - Percent-encoding
- Http Headers - RFC 7230 3.2.4. Field Parsing
So there is still an overall memory saving if the CLR provided an implementation that stored some strings in a more compact encoding that only takes 1 byte per character (ASCII or even ISO-8859-1 (Latin-1)) and the rest as Unicode (2 bytes per character).
Aside: If you are wondering “Why does C# use UTF-16 for strings?” Eric Lippert has a great post on this exact subject and Jon Skeet has something interesting to say about the subject in “Of Memory and Strings”
Real-world data
In theory this is all well and good, but what about in practice, what about a real-world example?
Well Nick Craver a developer at Stack Overflow was kind enough to run my Heap Analyser tool one of their memory dumps:
.NET Memory Dump Heap Analyser - created by Matt Warren - github.com/mattwarren
Found CLR Version: v4.6.1055.00
...
Overall 30,703,367 "System.String" objects take up 4,320,235,704 bytes (4,120.10 MB)
Of this underlying byte arrays (as Unicode) take up 3,521,948,162 bytes (3,358.79 MB)
Remaining data (object headers, other fields, etc) is 798,287,542 bytes (761.31 MB), at 26 bytes per object
Actual Encoding that the "System.String" could be stored as (with corresponding data size)
3,347,868,352 bytes are ASCII
5,078,902 bytes are ISO-8859-1 (Latin-1)
169,000,908 bytes are Unicode (UTF-16)
Total: 3,521,948,162 bytes (expected: 3,521,948,162)
Compression Summary:
1,676,473,627 bytes Compressed (to ISO-8859-1 (Latin-1))
169,000,908 bytes Uncompressed (as Unicode/UTF-16)
30,703,367 bytes EXTRA to enable compression (one byte field, per "System.String" object)
Total: 1,876,177,902 bytes, compared to 3,521,948,162 before compression
(The full output is available)
Here we can see that there are over 30 million strings in memory, taking up 4,120 MB out of a total heap size of 13,232 MB (just over 30%).
Further more we can see that the raw data used by the strings (excluding the CLR Object headers) takes up 3,358 MB when encoded as Unicode. However if the relevant strings were compacted to ASCII/Latin-1 only 1,789 MB would be needed to store them, a pretty impressive saving!
A proposal for compact strings in the CLR
I learnt about the idea of “Compact Strings” when reading about how they were implemented in Java and so I put together a proposal for an implementation in the CLR (isn’t .NET OSS Great!!).
Turns out that Vance Morrison (Performance Architect on the .NET Runtime Team) has been thinking about the same idea for quite a while:
To answer @mattwarren question on whether changing the internal representation of a string has been considered before, the short answer is YES. In fact it has been a pet desire of mine for probably over a decade now.
He also confirmed that they’ve done their homework and found that a significant amount of strings could be compacted:
What was clear now and has held true for quite sometime is that: Typical apps have 20% of their GC heap as strings. Most of the 16 bit characters have 0 in their upper byte. Thus you can save 10% of typical heaps by encoding in various ways that eliminate these pointless upper bytes.
It’s worth reading his entire response if you are interested in the full details of the proposal, including the trade-offs, benefits and drawbacks.
Implementation details
At a high-level the proposal would allow to strings to be stored in 2 formats:
- Regular - i.e. Unicode encoded, as they are currently stored by the CLR
- Compact - ASCII, ISO-8859-1 (Latin-1) or even another format
When you create a string, the constructor would determine the most efficient encoding and encode the data in that format. The formant used would then be stored in a field, so that the encoding is always known (CLR strings are immutable). That means that each method within the string class can use this field to determine how it operates, for instance the pseudo-code for the Equals method is shown below:
public boolean Equals(string other)
{
if (this.type != other.type)
return false;
if (type == ASCII)
return StringASCII.Equals(this, other);
else
return StringLatinUTF16.Equals(this, other);
}
This shows a nice property of having strings in two formats; some operations can be short-circuited, because we know that strings stored in different encodings won’t be the same.
Advantages
- less overall memory usage (as-per @davidfowl “At the top of every ASP.NET profile… strings!”)
- strings become more cache-friendly, which may give better performance
Disadvantages
- Makes some operations slower due to the extra
if (type == ...)check needed - Breaks the
fixedkeyword, as well as COM and P/Invoke interop that relies on the current string layout/format - If very few strings in the application can be compacted, this will have an overhead for no gain
Next steps
In his reply Vance Morrison highlighted that solving the issue with the fixed keyword was a first step, because that has a hard dependency on the current string layout. Once that’s done the real work of making large, sweeping changes to the CLR can be done:
The main challenge is dealing with fixed, but there is also frankly at least a few man-months of simply dealing with the places in the runtime where we took a dependency on the layout of string (in the runtime, interop, and things like stringbuilder, and all the uses of ‘fixed’ in corefx).
Thus it IS doable, but it is at least moderately expensive (man months), and the payoff is non-trivial but not huge.
So stay tuned, one day we might have a more compact, more efficient implementation of strings in the CLR, yay!!
Further Reading
- An implementation of this idea done in the Mono runtime, with accompanying discussion
- More info from Eric Lippert on why .NET strings are laid out as they are
- UTF-8 string Library currently being developed in the CoreFX Labs.
- Report produced by several Oracle Engineers: “String Density: Performance and Footprint”
- Report on “State of String Density performance (May 5, 2015)” in Java
- What was involved in optimising the Java implementation (tl;dr quite a lot!!)
- Python’s Flexible String Representation
Discuss this post on /r/programming