The Stack Overflow Tag Engine – Part 2
19 Aug 2015 - 1334 wordsI’ve added a Resources and Speaking page to my site, check them out if you want to learn more. There’s also a video available of my NDC London 2014 talk “Performance is a Feature!”.
Recap of Stack Overflow Tag Engine
This is the long-delayed part 2 of a mini-series looking at what it might take to build the Stack Overflow Tag Engine, if you haven’t read part 1, I recommend reading it first.
Since the first part was published, Stack Overflow published a nice performance report, giving some more stats on the Tag Engine Servers. As you can see they run the Tag Engine on some pretty powerful servers, but only have a peak CPU usage of 10%, which means there’s plenty of overhead available. It’s a nice way of being able to cope with surges in demand or busy times of the day.

Ignored Tag Preferences
In part 1, I only really covered the simple things, i.e. a basic search for all the questions that contain a given tag, along with multiple sort orders (by score, view count, etc). But the real Tag Engine does much more than that, for instance:
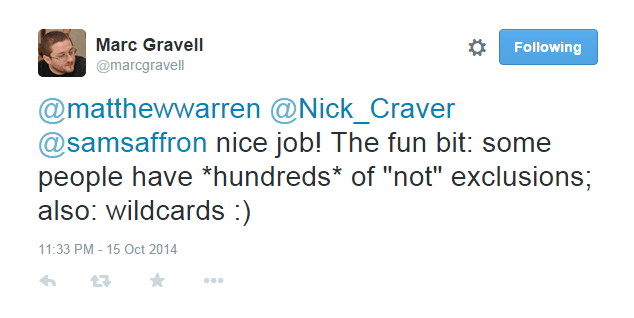
What is he talking about here? Well any time you do a tag search, after the actual search has been done per-user exclusions can then be applied. These exclusions are configurable and allow you to set “Ignored Tags”, i.e. tags that you don’t want to see questions for. Then when you do a search, it will exclude these questions from the results.
Note: it will let you know if there were questions excluded due to your preferences, which is a pretty nice user-experience. If that happens, you get this message: (it can also be configured so that matching questions are greyed out instead):

Now most people probably have just a few exclusions and maybe 10’s at most, but fortunately @leppie a Stack Overflow power-user got in touch with me and shared his list of preferences.
You’ll need to scroll across to appreciate this full extent of this list, but here’s some statistics to help you:
- It contains 3,753 items, of which 210 are wildcards (e.g. cocoa* or *hibernate*)
- The tags and wildcards expand to 7,677 tags in total (out of a possible 30,529 tags)
- There are 6,428,251 questions (out of 7,990,787) that have at least one of the 7,677 tags in them!
Wildcards
If you want to see the wildcard expansion in action you can visit the url’s below:
- *java*
- [facebook-javascript-sdk] [java] [java.util.scanner] [java-7] [java-8] [javabeans] [javac] [javadoc] [java-ee] [java-ee-6] [javafx] [javafx-2] [javafx-8] [java-io] [javamail] [java-me] [javascript] [javascript-events] [javascript-objects] [java-web-start]
- .net*
- [.net] [.net-1.0] [.net-1.1] [.net-2.0] [.net-3.0] [.net-3.5] [.net-4.0] [.net-4.5] [.net-4.5.2] [.net-4.6] [.net-assembly] [.net-cf-3.5] [.net-client-profile] [.net-core] [.net-framework-version] [.net-micro-framework] [.net-reflector] [.net-remoting] [.net-security] [.nettiers]
Now a simple way of doing these matches is the following, i.e. loop through the wildcards and compare each one with every single tag to see if it could be expanded to match that tag. (IsActualMatch(..) is a simple method that does a basic string StartsWith, EndsWith or Contains as appropriate)
var expandedTags = new HashSet();
foreach (var wildcard in wildcardsToExpand)
{
if (IsWildCard(tagToExpand))
{
var rawTagPattern = tagToExpand.Replace("*", "");
foreach (var tag in allTags)
{
if (IsActualMatch(tag, tagToExpand, rawTagPattern))
expandedTags.Add(tag);
}
}
else if (allTags.ContainsKey(tagToExpand))
{
expandedTags.Add(tagToExpand);
}
}
This works fine with a few wildcards, but it’s not very efficient. Even on a relatively small data-set containing 32,000 tags, it’s slow when comparing it to 210 wildcardsToExpand, taking over a second. After chatting to a few of the Stack Overflow developers on Twitter, they consider a Tag Engine query that takes longer than 500 milliseconds to be slow, so a second just to apply the wildcards is unacceptable.
Trigram Index
So can we do any better? Well it turns out that that there is a really nice technique for doing Regular Expression Matching with a Trigram Index that is used in Google Code Search. I’m not going to explain all the details, the linked page has a very readable explanation. But basically what you do is create an inverted index of the tags and search the index instead. That way you aren’t affected so much by the amount of wilcards, because you are only searching via an index rather than a full search that runs over the whole list of tags.
For instance when using Trigrams, the tags are initially split into 3 letter chunks, for instance the expansion for the tag javascript is shown below (‘_’ is added to denote the start/end of a word):
_ja, jav, ava, vas, asc, scr, cri, rip, ipt, pt_
Next you create an index of all the tags as trigrams and include the position of tag they came from so that you can reference back to it later:
- _ja -> { 0, 5, 6 }
- jav -> { 0, 5, 12 }
- ava -> { 0, 5, 6 }
- va_ -> { 0, 5, 11, 13 }
- _ne -> { 1, 10, 12 }
- net -> { 1, 10, 12, 15 }
- …
For example if you want to match any tags that contain java any where in the tag, i.e. a *java* wildcard query, you fetch the index values for jav and ava, which gives you (from above) these 2 matching index items:
- jav -> { 0, 5, 12 }
- ava -> { 0, 5, 6 }
and you now know that the tags with index 0 and 5 are the only matches because they have jav and ava (6 and 12 don’t have both)
Results
On my laptop I get the results shown below, where Contains is the naive way shown above and Regex is an attempt to make it faster by using compiled Regex queries (which was actually slower)
Expanded to 7,677 tags (Contains), took 721.51 ms
Expanded to 7,677 tags (Regex), took 1,218.69 ms
Expanded to 7,677 tags (Trigrams), took 54.21 ms
As you can see, the inverted index using Trigrams is a clear winner. If you are interested, the source code is available on GitHub.
In this post I showed one way that the Tag Engine could implement wildcards matching. As I don’t work at Stack Overflow there’s no way of knowing if they use the same method or not, but at the very least my method is pretty quick!
Future Posts
But there’s still more things to implement, in future posts I hope to cover the following:
- Complex boolean queries, i.e. questions tagged “c# OR .NET”, “.net AND (NOT jquery)” and how to make them fast
- How a DDOS attack on TagServer might have been caused
In October, we had a situation where a flood of crafted requests were causing high resource utilization on our Tag Engine servers, which is our internal application for associating questions and tags in a high-performance way.