Stack Overflow - performance lessons (part 1)
01 Sep 2014 - 1106 wordsThis post is part of a semi-regular series, you can find the other entries here and here
Before diving into any of the technical or coding aspects of performance, it is really important to understand that the main lesson to take-away from Stack Overflow (the team/product) is that they take performance seriously. You can see this from the blog post that Jeff Atwood wrote, it’s a part of their culture and has been from the beginning:

But anyone can come up with a catchy line like “Performance is a Feature!!”, it only means something if you actually carry it out. Well it’s clear that Stack Overflow have done just this, not only is it a Top 100 website, but they’ve done the whole thing with very few servers and several of those are running at only 15% of their capacity, so they can scale up if needed and/or deal with large traffic bursts.
Update (2/9/2014 9:25:35 AM): Nick Craver tweeted me to say that the High Scalability post is a bad summarisation (apparently they have got things wrong before), so take what it says with a grain of salt!
Aside: If you want even more information about their set-up, I definitely recommend reading the Hacker News discussion and this post from Nick Craver, one of the Stack Overflow developers.
Interestingly they have gone for scale-up rather than scale-out, by building their own servers instead of using cloud hosting. The reason for this, just to get better performance!
Why do I choose to build and colocate servers? Primarily to achieve maximum performance. That’s the one thing you consistently just do not get from cloud hosting solutions unless you are willing to pay a massive premium, per month, forever: raw, unbridled performance….
Taking performance seriously
It’s also worth noting that they are even prepared to sacrifice the ability to unit test their code, because it gives them better performance.
- Garbage collection driven programming. SO goes to great lengths to reduce garbage collection costs, skipping practices like TDD, avoiding layers of abstraction, and using static methods. While extreme, the result is highly performing code. When you’re doing hundreds of millions of objects in a short window, you can actually measure pauses in the app domain while GC runs. These have a pretty decent impact on request performance.
Now, this isn’t for everyone and even suggesting that unit testing isn’t needed or useful tends to produce strong reactions. But you can see that they are making an informed trade-off and they are prepared to go against the conventional wisdom (“write code that is unit-testing friendly”), because it gives them the extra performance they want. One caveat is that they are in a fairly unique position, they have passionate users that are willing to act as beta-testers, so having less unit test might not harm them, not everyone has that option!
- To get around garbage collection problems, only one copy of a class used in templates are created and kept in a cache. Everything is measured, including GC operation, from statistics it is known that layers of indirection increase GC pressure to the point of noticeable slowness.
For a more detailed discussion on why this approach to coding can make a difference to GC pressure, see here and here.
Sharing and doing everything out in the open
Another non-technical lesson is that Stack Overflow are committed to doing things out in the open and sharing what they create as code or lessons-learnt blog posts. Their list of open source projects includes:
- MiniProfiler - which gives developers an overview of where the time is being spent when a page renders (front-end, back-end, database, etc)
- Dapper - developed because Entity Framework imposed too large an overhead when materialising the results of a SQL query into POCO’s
- Jil - a newly release JSON serialisation/library, developed so that they can get the best possible performance. JSON parsing and serialisation must be a very common operation across their web-servers, so shaving off microseconds from the existing libraries is justified.
- TagServer - a custom .NET service that was written to make the complex tag searches quicker than they would be if done directly in SQL Server.
- Opserver - fully featured monitoring tool, giving their operation engineers a deep-insight into what their servers are doing in production.
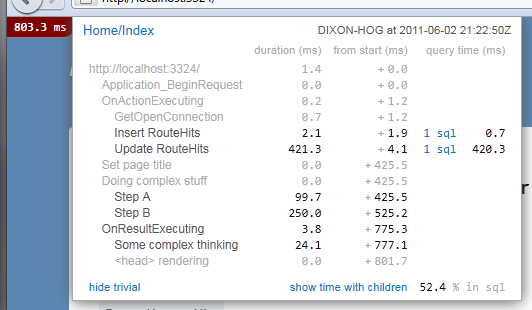
All these examples show that they are not afraid to write their own tools when the existing ones aren’t up-to scratch, don’t have the features they need or don’t give the performance they require.
Measure, profile and display
As shown by the development of Opserver, they care about measuring performance accurately even (or especially) in production. Take a look at the images below and you can see not only the detailed level of information they keep, but how it is displayed in a way that makes is easy to see what is going on (there are also more screenshots available).
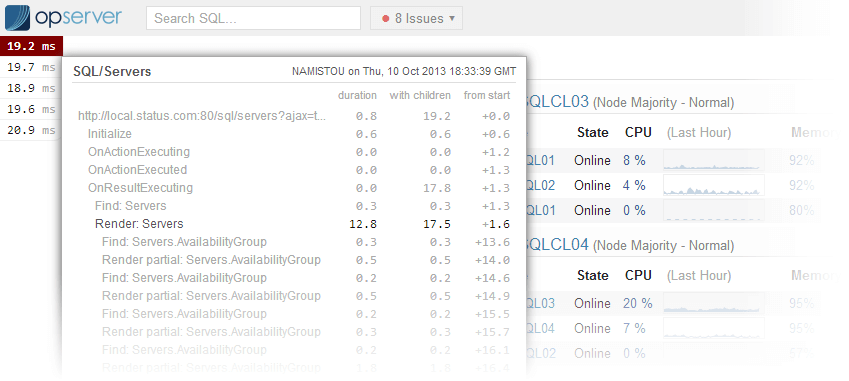
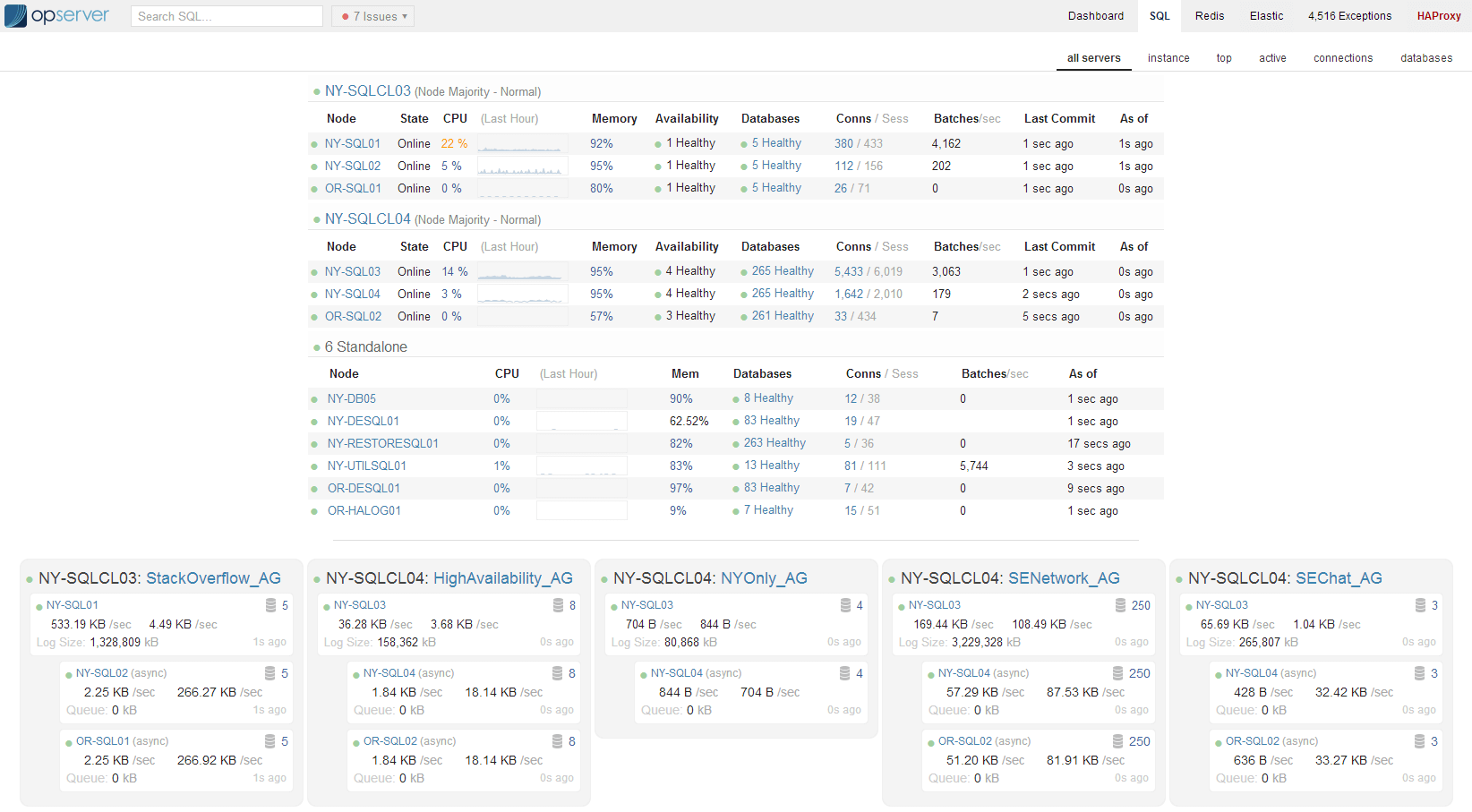
Finally I really like their guidelines for achieving good observability in a production system. They serve as a really good check-list of things you need to do if you want to have any chance of knowing what your system up to in production. I would image these steps and the resulting screens they designed into Opserver have been built up over several years of monitoring and fixing issues in the Stack Overflow sites, so they are battle-hardened!
5 Steps to Achieving Good Observability: In order to achieve good observability an SRE team (often in conduction with the rest of the organization) needs to do the following steps.
- Instrument your systems by publishing metrics and events
- Gather those metrics and events in a queryable data store(s)
- Make that data readily accessible
- Highlight metrics that are, or are trending towards abnormal or out of bounds behavior
- Establish the resources to drill down into abnormal or out of bounds behavior
Next time
Next time I’ll look at some concrete examples of performance lessons for the open source projects that SO have set-up, including the crazy tricks they use in Jil, their JSON serialisation library.